
Foundations of Robot Learning, Control, and Planning
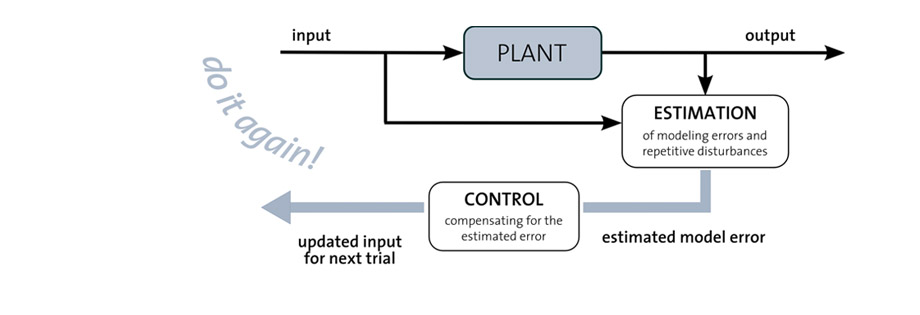

Learning algorithms hold great promise for improving a robot’s performance whenever a-priori models are not sufficiently accurate. We have developed learning controllers of different complexity ranging from controllers that improve the execution of a specific task by iteratively updating the reference input, to task-independent schemes that update the underlying robot model whenever new data becomes available. However, all learning controllers have the following characteristics:
- they combine a-priori model information with experimental data,
- they make no major, a-priori assumptions about the unknown effects to be learned, and
- they have been tested extensively on state-of-the-art robotic platforms.
Related Publications
Model Learning with Gaussian Processes
This paper presents a model-learning method for Stochastic Model Predictive Control (SMPC) that is both accurate and computationally efficient. We assume that the control input affects the robot dynamics through an unknown (but invertable) nonlinear function. By learning this unknown function and its inverse, we can use the value of the function as a new control input (which we call the input feature) that is optimised by SMPC in place of the original control input. This removes the need to evaluate a function approximator for the unknown function during optimisation in SMPC (where it would be evaluated many times), reducing the computational cost. The learned inverse is evaluated only once at each sampling time to convert the optimal input feature from SMPC to a control input to apply to the system. We assume that the remaining unknown dynamics can be accurately represented as a model that is linear in a set of coefficients, which enables fast adaptation to new conditions. We demonstrate our approach in experiments on a large ground robot using a stereo camera for localisation.
@article{mckinnon-ral21,
title = {Meta Learning With Paired Forward and Inverse Models for Efficient Receding Horizon Control},
author = {Christopher D. McKinnon and Angela P. Schoellig},
journal = {{IEEE Robotics and Automation Letters}},
year = {2021},
volume = {6},
number = {2},
pages = {3240--3247},
doi = {10.1109/LRA.2021.3063957},
urllink = {https://ieeexplore.ieee.org/document/9369887},
abstract = {This paper presents a model-learning method for Stochastic Model Predictive Control (SMPC) that is both accurate and computationally efficient. We assume that the control input affects the robot dynamics through an unknown (but invertable) nonlinear function. By learning this unknown function and its inverse, we can use the value of the function as a new control input (which we call the input feature) that is optimised by SMPC in place of the original control input. This removes the need to evaluate a function approximator for the unknown function during optimisation in SMPC (where it would be evaluated many times), reducing the computational cost. The learned inverse is evaluated only once at each sampling time to convert the optimal input feature from SMPC to a control input to apply to the system. We assume that the remaining unknown dynamics can be accurately represented as a model that is linear in a set of coefficients, which enables fast adaptation to new conditions. We demonstrate our approach in experiments on a large ground robot using a stereo camera for localisation.}
} ![]() Exploiting differential flatness for robust learning-based tracking control using Gaussian processesM. Greeff and A. SchoelligIEEE Control Systems Letters, vol. 5, iss. 4, p. 1121–1126, 2021.
Exploiting differential flatness for robust learning-based tracking control using Gaussian processesM. Greeff and A. SchoelligIEEE Control Systems Letters, vol. 5, iss. 4, p. 1121–1126, 2021.
![]()
![]()
![]()
![]()
![]()
Learning-based control has shown to outperform conventional model-based techniques in the presence of model uncertainties and systematic disturbances. However, most state-of-the-art learning-based nonlinear trajectory tracking controllers still lack any formal guarantees. In this letter, we exploit the property of differential flatness to design an online, robust learning-based controller to achieve both high tracking performance and probabilistically guarantee a uniform ultimate bound on the tracking error. A common control approach for differentially flat systems is to try to linearize the system by using a feedback (FB) linearization controller designed based on a nominal system model. Performance and safety are limited by the mismatch between the nominal model and the actual system. Our proposed approach uses a nonparametric Gaussian Process (GP) to both improve FB linearization and quantify, probabilistically, the uncertainty in our FB linearization. We use this probabilistic bound in a robust linear quadratic regulator (LQR) framework. Through simulation, we highlight that our proposed approach significantly outperforms alternative learning-based strategies that use differential flatness.
@article{greeff-lcss21,
title = {Exploiting Differential Flatness for Robust Learning-Based Tracking Control using {Gaussian} Processes},
author = {Melissa Greeff and Angela Schoellig},
journal = {{IEEE Control Systems Letters}},
year = {2021},
volume = {5},
number = {4},
pages = {1121--1126},
doi = {10.1109/LCSYS.2020.3009177},
urllink = {https://ieeexplore.ieee.org/document/9140024},
urlvideo = {https://youtu.be/ZFzZkKjQ3qw},
abstract = {Learning-based control has shown to outperform conventional model-based techniques in the presence of model uncertainties and systematic disturbances. However, most state-of-the-art learning-based nonlinear trajectory tracking controllers still lack any formal guarantees. In this letter, we exploit the property of differential flatness to design an online, robust learning-based controller to achieve both high tracking performance and probabilistically guarantee a uniform ultimate bound on the tracking error. A common control approach for differentially flat systems is to try to linearize the system by using a feedback (FB) linearization controller designed based on a nominal system model. Performance and safety are limited by the mismatch between the nominal model and the actual system. Our proposed approach uses a nonparametric Gaussian Process (GP) to both improve FB linearization and quantify, probabilistically, the uncertainty in our FB linearization. We use this probabilistic bound in a robust linear quadratic regulator (LQR) framework. Through simulation, we highlight that our proposed approach significantly outperforms alternative learning-based strategies that use differential flatness.}
} ![]() Learning a stability filter for uncertain differentially flat systems using Gaussian processesM. Greeff, A. W. Hall, and A. P. Schoelligin Proc. of the IEEE Conference on Decision and Control (CDC), 2021, p. 789–794.
Learning a stability filter for uncertain differentially flat systems using Gaussian processesM. Greeff, A. W. Hall, and A. P. Schoelligin Proc. of the IEEE Conference on Decision and Control (CDC), 2021, p. 789–794.
![]()
![]()
![]()
Many physical system models exhibit a structural property known as differential flatness. Intuitively, differential flatness allows us to separate the system’s nonlinear dynamics into a linear dynamics component and a nonlinear term. In this work, we exploit this structure and propose using a nonparametric Gaussian Process (GP) to learn the unknown nonlinear term. We use this GP in an optimization problem to optimize for an input that is most likely to feedback linearize the system (i.e., cancel this nonlinear term). This optimization is subject to input constraints and a stability filter, described by an uncertain Control Lyapunov Function (CLF), which prob- abilistically guarantees exponential trajectory tracking when possible. Furthermore, for systems that are control-affine, we choose to express this structure in the selection of the kernel for the GP. By exploiting this selection, we show that the optimization problem is not only convex but can be efficiently solved as a second-order cone program. We compare our approach to related works in simulation and show that we can achieve similar performance at much lower computational cost.
@INPROCEEDINGS{greeff-cdc21,
author = {Melissa Greeff and Adam W. Hall and Angela P. Schoellig},
title = {Learning a Stability Filter for Uncertain Differentially Flat Systems using {Gaussian} Processes},
booktitle = {{Proc. of the IEEE Conference on Decision and Control (CDC)}},
year = {2021},
pages = {789--794},
doi = {10.1109/CDC45484.2021.9683661},
abstract = {Many physical system models exhibit a structural property known as differential flatness. Intuitively, differential flatness allows us to separate the system’s nonlinear dynamics into a linear dynamics component and a nonlinear term. In this work, we exploit this structure and propose using a nonparametric Gaussian Process (GP) to learn the unknown nonlinear term. We use this GP in an optimization problem to optimize for an input that is most likely to feedback linearize the system (i.e., cancel this nonlinear term). This optimization is subject to input constraints and a stability filter, described by an uncertain Control Lyapunov Function (CLF), which prob- abilistically guarantees exponential trajectory tracking when possible. Furthermore, for systems that are control-affine, we choose to express this structure in the selection of the kernel for the GP. By exploiting this selection, we show that the optimization problem is not only convex but can be efficiently solved as a second-order cone program. We compare our approach to related works in simulation and show that we can achieve similar performance at much lower computational cost.},
} ![]() Learning-based nonlinear model predictive control to improve vision-based mobile robot path-tracking in challenging outdoor environmentsC. J. Ostafew, A. P. Schoellig, and T. D. Barfootin Proc. of the IEEE International Conference on Robotics and Automation (ICRA), 2014, pp. 4029-4036.
Learning-based nonlinear model predictive control to improve vision-based mobile robot path-tracking in challenging outdoor environmentsC. J. Ostafew, A. P. Schoellig, and T. D. Barfootin Proc. of the IEEE International Conference on Robotics and Automation (ICRA), 2014, pp. 4029-4036.
![]()
![]()
![]()
![]()
This paper presents a Learning-based Nonlinear Model Predictive Control (LB-NMPC) algorithm for an autonomous mobile robot to reduce path-tracking errors over repeated traverses along a reference path. The LB-NMPC algorithm uses a simple a priori vehicle model and a learned disturbance model. Disturbances are modelled as a Gaussian Process (GP) based on experience collected during previous traversals as a function of system state, input and other relevant variables. Modelling the disturbance as a GP enables interpolation and extrapolation of learned disturbances, a key feature of this algorithm. Localization for the controller is provided by an on-board, vision-based mapping and navigation system enabling operation in large-scale, GPS-denied environments. The paper presents experimental results including over 1.8 km of travel by a four-wheeled, 50 kg robot travelling through challenging terrain (including steep, uneven hills) and by a six-wheeled, 160 kg robot learning disturbances caused by unmodelled dynamics at speeds ranging from 0.35 m/s to 1.0 m/s. The speed is scheduled to balance trial time, path-tracking errors, and localization reliability based on previous experience. The results show that the system can start from a generic a priori vehicle model and subsequently learn to reduce vehicle- and trajectory-specific path-tracking errors based on experience.
@INPROCEEDINGS{ostafew-icra14,
author = {Chris J. Ostafew and Angela P. Schoellig and Timothy D. Barfoot},
title = {Learning-based nonlinear model predictive control to improve vision-based mobile robot path-tracking in challenging outdoor environments},
booktitle = {{Proc. of the IEEE International Conference on Robotics and Automation (ICRA)}},
pages = {4029-4036},
year = {2014},
doi = {10.1109/ICRA.2014.6907444},
urlvideo = {https://youtu.be/MwVElAn95-M?list=PLC12E387419CEAFF2},
abstract = {This paper presents a Learning-based Nonlinear Model Predictive Control (LB-NMPC) algorithm for an autonomous mobile robot to reduce path-tracking errors over repeated traverses along a reference path. The LB-NMPC algorithm uses a simple a priori vehicle model and a learned disturbance model. Disturbances are modelled as a Gaussian Process (GP) based on experience collected during previous traversals as a function of system state, input and other relevant variables. Modelling the disturbance as a GP enables interpolation and extrapolation of learned disturbances, a key feature of this algorithm. Localization for the controller is provided by an on-board, vision-based mapping and navigation system enabling operation in large-scale, GPS-denied environments. The paper presents experimental results including over 1.8 km of travel by a four-wheeled, 50 kg robot travelling through challenging terrain (including steep, uneven hills) and by a six-wheeled, 160 kg robot learning disturbances caused by unmodelled dynamics at speeds ranging from 0.35 m/s to 1.0 m/s. The speed is scheduled to balance trial time, path-tracking errors, and localization reliability based on previous experience. The results show that the system can start from a generic a priori vehicle model and subsequently learn to reduce vehicle- and trajectory-specific path-tracking errors based on experience.}
}Safe and Robust Learning Control
Learning models or control policies from data has become a powerful tool to improve the performance of uncertain systems. While a strong focus has been placed on increasing the amount and quality of data to improve performance, data can never fully eliminate uncertainty, making feedback necessary to ensure stability and performance. We show that the control frequency at which the input is recalculated is a crucial design parameter, yet it has hardly been considered before. We address this gap by combining probabilistic model learning and sampled-data control. We use Gaussian processes (GPs) to learn a continuous-time model and compute a corresponding discrete-time controller. The result is an uncertain sampled-data control system, for which we derive robust stability conditions. We formulate semidefinite programs to compute the minimum control frequency required for stability and to optimize performance. As a result, our approach enables us to study the effect of both control frequency and data on stability and closed-loop performance. We show in numerical simulations of a quadrotor that performance can be improved by increasing either the amount of data or the control frequency, and that we can trade off one for the other. For example, by increasing the control frequency by 33\%, we can reduce the number of data points by half while still achieving similar performance.
@inproceedings{roemer-acc24,
author={Ralf R{\"o}mer and Lukas Brunke and SiQi Zhou and Angela P. Schoellig},
booktitle = {{Proc. of the American Control Conference (ACC)}},
title={Is Data All That Matters? {The} Role of Control Frequency for Learning-Based Sampled-Data Control of Uncertain Systems},
year={2024},
note={Accepted},
urllink={https://arxiv.org/abs/2403.09504},
urlcode={https://github.com/ralfroemer99/lb_sd},
abstract = {Learning models or control policies from data has become a powerful tool to improve the performance of uncertain systems. While a strong focus has been placed on increasing the amount and quality of data to improve performance, data can never fully eliminate uncertainty, making feedback necessary to ensure stability and performance. We show that the control frequency at which the input is recalculated is a crucial design parameter, yet it has hardly been considered before. We address this gap by combining probabilistic model learning and sampled-data control. We use Gaussian processes (GPs) to learn a continuous-time model and compute a corresponding discrete-time controller. The result is an uncertain sampled-data control system, for which we derive robust stability conditions. We formulate semidefinite programs to compute the minimum control frequency required for stability and to optimize performance. As a result, our approach enables us to study the effect of both control frequency and data on stability and closed-loop performance. We show in numerical simulations of a quadrotor that performance can be improved by increasing either the amount of data or the control frequency, and that we can trade off one for the other. For example, by increasing the control frequency by 33\%, we can reduce the number of data points by half while still achieving similar performance.}
} ![]() Optimized control invariance conditions for uncertain input-constrained nonlinear control systemsL. Brunke, S. Zhou, M. Che, and A. P. SchoelligIEEE Control Systems Letters, vol. 8, p. 157–162, 2024.
Optimized control invariance conditions for uncertain input-constrained nonlinear control systemsL. Brunke, S. Zhou, M. Che, and A. P. SchoelligIEEE Control Systems Letters, vol. 8, p. 157–162, 2024.
![]()
![]()
![]()
Providing safety guarantees for learning-based controllers is important for real-world applications. One approach to realizing safety for arbitrary control policies is safety filtering. If necessary, the filter modifies control inputs to ensure that the trajectories of a closed-loop system stay within a given state constraint set for all future time, referred to as the set being positive invariant or the system being safe. Under the assumption of fully known dynamics, safety can be certified using control barrier functions (CBFs). However, the dynamics model is often either unknown or only partially known in practice. Learning-based methods have been proposed to approximate the CBF condition for unknown or uncertain systems from data; however, these techniques do not account for input constraints and, as a result, may not yield a valid CBF condition to render the safe set invariant. In this letter, we study conditions that guarantee control invariance of the system under input constraints and propose an optimization problem to reduce the conservativeness of CBF-based safety filters. Building on these theoretical insights, we further develop a probabilistic learning approach that allows us to build a safety filter that guarantees safety for uncertain, input-constrained systems with high probability. We demonstrate the efficacy of our proposed approach in simulation and real-world experiments on a quadrotor and show that we can achieve safe closed-loop behavior for a learned system while satisfying state and input constraints.
@article{brunke-lcss24,
author={Lukas Brunke and Siqi Zhou and Mingxuan Che and Angela P. Schoellig},
journal={{IEEE Control Systems Letters}},
title={Optimized Control Invariance Conditions for Uncertain Input-Constrained Nonlinear Control Systems},
year={2024},
volume={8},
number={},
pages={157--162},
doi={10.1109/LCSYS.2023.3344138},
abstract={Providing safety guarantees for learning-based controllers is important for real-world applications. One approach to realizing safety for arbitrary control policies is safety filtering. If necessary, the filter modifies control inputs to ensure that the trajectories of a closed-loop system stay within a given state constraint set for all future time, referred to as the set being positive invariant or the system being safe. Under the assumption of fully known dynamics, safety can be certified using control barrier functions (CBFs). However, the dynamics model is often either unknown or only partially known in practice. Learning-based methods have been proposed to approximate the CBF condition for unknown or uncertain systems from data; however, these techniques do not account for input constraints and, as a result, may not yield a valid CBF condition to render the safe set invariant. In this letter, we study conditions that guarantee control invariance of the system under input constraints and propose an optimization problem to reduce the conservativeness of CBF-based safety filters. Building on these theoretical insights, we further develop a probabilistic learning approach that allows us to build a safety filter that guarantees safety for uncertain, input-constrained systems with high probability. We demonstrate the efficacy of our proposed approach in simulation and real-world experiments on a quadrotor and show that we can achieve safe closed-loop behavior for a learned system while satisfying state and input constraints.}
} ![]() Multi-step model predictive safety filters: reducing chattering by increasing the prediction horizonF. Pizarro Bejarano, L. Brunke, and A. P. Schoelligin Proc. of the IEEE Conference on Decision and Control (CDC), 2023, p. 4723–4730.
Multi-step model predictive safety filters: reducing chattering by increasing the prediction horizonF. Pizarro Bejarano, L. Brunke, and A. P. Schoelligin Proc. of the IEEE Conference on Decision and Control (CDC), 2023, p. 4723–4730.
![]()
![]()
![]()
Learning-based controllers have demonstrated su-perior performance compared to classical controllers in various tasks. However, providing safety guarantees is not trivial. Safety, the satisfaction of state and input constraints, can be guaranteed by augmenting the learned control policy with a safety filter. Model predictive safety filters (MPSFs) are a common safety filtering approach based on model predictive control (MPC). MPSFs seek to guarantee safety while minimizing the difference between the proposed and applied inputs in the immediate next time step. This limited foresight can lead to jerky motions and undesired oscillations close to constraint boundaries, known as chattering. In this paper, we reduce chattering by considering input corrections over a longer horizon. Under the assumption of bounded model uncertainties, we prove recursive feasibility using techniques from robust MPC. We verified the proposed approach in both extensive simulation and quadrotor exper-iments. In experiments with a Crazyflie 2.0 drone, we show that, in addition to preserving the desired safety guarantees, the proposed MPSF reduces chattering by more than a factor of 4 compared to previous MPSF formulations.
@inproceedings{pizarro-cdc23,
author={Pizarro Bejarano, Federico and Brunke, Lukas and Schoellig, Angela P.},
booktitle={{Proc. of the IEEE Conference on Decision and Control (CDC)}},
title={Multi-Step Model Predictive Safety Filters: Reducing Chattering by Increasing the Prediction Horizon},
year={2023},
pages={4723--4730},
doi={10.1109/CDC49753.2023.10383734},
abstract={Learning-based controllers have demonstrated su-perior performance compared to classical controllers in various tasks. However, providing safety guarantees is not trivial. Safety, the satisfaction of state and input constraints, can be guaranteed by augmenting the learned control policy with a safety filter. Model predictive safety filters (MPSFs) are a common safety filtering approach based on model predictive control (MPC). MPSFs seek to guarantee safety while minimizing the difference between the proposed and applied inputs in the immediate next time step. This limited foresight can lead to jerky motions and undesired oscillations close to constraint boundaries, known as chattering. In this paper, we reduce chattering by considering input corrections over a longer horizon. Under the assumption of bounded model uncertainties, we prove recursive feasibility using techniques from robust MPC. We verified the proposed approach in both extensive simulation and quadrotor exper-iments. In experiments with a Crazyflie 2.0 drone, we show that, in addition to preserving the desired safety guarantees, the proposed MPSF reduces chattering by more than a factor of 4 compared to previous MPSF formulations.}
} Swarm-GPT: combining large language models with safe motion planning for robot choreography designA. Jiao, T. P. Patel, S. Khurana, A. Korol, L. Brunke, V. K. Adajania, U. Culha, S. Zhou, and A. P. SchoelligExtended Abstract in the 6th Robot Learning Workshop at the Conference on Neural Information Processing Systems (NeurIPS), 2023.
![]()
![]()
![]()
![]()
This paper presents Swarm-GPT, a system that integrates large language models (LLMs) with safe swarm motion planning – offering an automated and novel approach to deployable drone swarm choreography. Swarm-GPT enables users to automatically generate synchronized drone performances through natural language instructions. With an emphasis on safety and creativity, Swarm-GPT addresses a critical gap in the field of drone choreography by integrating the creative power of generative models with the effectiveness and safety of model-based planning algorithms. This goal is achieved by prompting the LLM to generate a unique set of waypoints based on extracted audio data. A trajectory planner processes these waypoints to guarantee collision-free and feasible motion. Results can be viewed in simulation prior to execution and modified through dynamic re-prompting. Sim-to-real transfer experiments demonstrate Swarm-GPT’s ability to accurately replicate simulated drone trajectories, with a mean sim-to-real root mean square error (RMSE) of 28.7 mm. To date, Swarm-GPT has been successfully showcased at three live events, exemplifying safe real-world deployment of pre-trained models.
@MISC{jiao-neurips23,
author = {Aoran Jiao and Tanmay P. Patel and Sanjmi Khurana and Anna-Mariya Korol and Lukas Brunke and Vivek K. Adajania and Utku Culha and Siqi Zhou and Angela P. Schoellig},
title = {{Swarm-GPT}: Combining Large Language Models with Safe Motion Planning for Robot Choreography Design},
year = {2023},
howpublished = {Extended Abstract in the 6th Robot Learning Workshop at the Conference on Neural Information Processing Systems (NeurIPS)},
urllink = {https://arxiv.org/abs/2312.01059},
abstract = {This paper presents Swarm-GPT, a system that integrates large language models (LLMs) with safe swarm motion planning - offering an automated and novel approach to deployable drone swarm choreography. Swarm-GPT enables users to automatically generate synchronized drone performances through natural language instructions. With an emphasis on safety and creativity, Swarm-GPT addresses a critical gap in the field of drone choreography by integrating the creative power of generative models with the effectiveness and safety of model-based planning algorithms. This goal is achieved by prompting the LLM to generate a unique set of waypoints based on extracted audio data. A trajectory planner processes these waypoints to guarantee collision-free and feasible motion. Results can be viewed in simulation prior to execution and modified through dynamic re-prompting. Sim-to-real transfer experiments demonstrate Swarm-GPT's ability to accurately replicate simulated drone trajectories, with a mean sim-to-real root mean square error (RMSE) of 28.7 mm. To date, Swarm-GPT has been successfully showcased at three live events, exemplifying safe real-world deployment of pre-trained models.},
} ![]() Safe-control-gym: a unified benchmark suite for safe learning-based control and reinforcement learning in roboticsZ. Yuan, A. W. Hall, S. Zhou, M. G. Lukas Brunke and, J. Panerati, and A. P. SchoelligIEEE Robotics and Automation Letters, vol. 7, iss. 4, pp. 11142-11149, 2022.
Safe-control-gym: a unified benchmark suite for safe learning-based control and reinforcement learning in roboticsZ. Yuan, A. W. Hall, S. Zhou, M. G. Lukas Brunke and, J. Panerati, and A. P. SchoelligIEEE Robotics and Automation Letters, vol. 7, iss. 4, pp. 11142-11149, 2022.
![]()
![]()
![]()
![]()
In recent years, both reinforcement learning and learning-based control—as well as the study of their safety, which is crucial for deployment in real-world robots—have gained significant traction. However, to adequately gauge the progress and applicability of new results, we need the tools to equitably compare the approaches proposed by the controls and reinforcement learning communities. Here, we propose a new open-source benchmark suite, called safe-control-gym, supporting both model-based and data-based control techniques. We provide implementations for three dynamic systems—the cart-pole, the 1D, and 2D quadrotor—and two control tasks—stabilization and trajectory tracking. We propose to extend OpenAI’s Gym API—the de facto standard in reinforcement learning research—with (i) the ability to specify (and query) symbolic dynamics and (ii) constraints, and (iii) (repeatably) inject simulated disturbances in the control inputs, state measurements, and inertial properties. To demonstrate our proposal and in an attempt to bring research communities closer together, we show how to use safe-control-gym to quantitatively compare the control performance, data efficiency, and safety of multiple approaches from the fields of traditional control, learning-based control, and reinforcement learning.
@article{yuan-ral22,
author={Zhaocong Yuan and Adam W. Hall and Siqi Zhou and Lukas Brunke and, Melissa Greeff and Jacopo Panerati and Angela P. Schoellig},
title={safe-control-gym: a Unified Benchmark Suite for Safe Learning-based Control and Reinforcement Learning in Robotics},
journal = {{IEEE Robotics and Automation Letters}},
year = {2022},
volume={7},
number={4},
pages={11142-11149},
urllink = {https://ieeexplore.ieee.org/abstract/document/9849119/},
doi = {10.1109/LRA.2022.3196132},
abstract = {In recent years, both reinforcement learning and learning-based control—as well as the study of their safety, which is crucial for deployment in real-world robots—have gained significant traction. However, to adequately gauge the progress and applicability of new results, we need the tools to equitably compare the approaches proposed by the controls and reinforcement learning communities. Here, we propose a new open-source benchmark suite, called safe-control-gym, supporting both model-based and data-based control techniques. We provide implementations for three dynamic systems—the cart-pole, the 1D, and 2D quadrotor—and two control tasks—stabilization and trajectory tracking. We propose to extend OpenAI’s Gym API—the de facto standard in reinforcement learning research—with (i) the ability to specify (and query) symbolic dynamics and (ii) constraints, and (iii) (repeatably) inject simulated disturbances in the control inputs, state measurements, and inertial properties. To demonstrate our proposal and in an attempt to bring research communities closer together, we show how to use safe-control-gym to quantitatively compare the control performance, data efficiency, and safety of multiple approaches from the fields of traditional control, learning-based control, and reinforcement learning.}
} ![]() Safe learning in robotics: from learning-based control to safe reinforcement learningL. Brunke, M. Greeff, A. W. Hall, Z. Yuan, S. Zhou, J. Panerati, and A. P. SchoelligAnnual Review of Control, Robotics, and Autonomous Systems, vol. 5, iss. 1, 2022.
Safe learning in robotics: from learning-based control to safe reinforcement learningL. Brunke, M. Greeff, A. W. Hall, Z. Yuan, S. Zhou, J. Panerati, and A. P. SchoelligAnnual Review of Control, Robotics, and Autonomous Systems, vol. 5, iss. 1, 2022.
![]()
![]()
![]()
The last half decade has seen a steep rise in the number of contributions on safe learning methods for real-world robotic deployments from both the control and reinforcement learning communities. This article provides a concise but holistic review of the recent advances made in using machine learning to achieve safe decision-making under uncertainties, with a focus on unifying the language and frameworks used in control theory and reinforcement learning research. It includes learning-based control approaches that safely improve performance by learning the uncertain dynamics, reinforcement learning approaches that encourage safety or robustness, and methods that can formally certify the safety of a learned control policy. As data- and learning-based robot control methods continue to gain traction, researchers must understand when and how to best leverage them in real-world scenarios where safety is imperative, such as when operating in close proximity to humans. We highlight some of the open challenges that will drive the field of robot learning in the coming years, and emphasize the need for realistic physics-based benchmarks to facilitate fair comparisons between control and reinforcement learning approaches. Expected final online publication date for the Annual Review of Control, Robotics, and Autonomous Systems, Volume 5 is May 2022. Please see http://www.annualreviews.org/page/journal/pubdates for revised estimates.
@article{dsl-annurev22,
author = {Lukas Brunke and Melissa Greeff and Adam W. Hall and Zhaocong Yuan and Siqi Zhou and Jacopo Panerati and Angela P. Schoellig},
title = {Safe Learning in Robotics: From Learning-Based Control to Safe Reinforcement Learning},
journal = {{Annual Review of Control, Robotics, and Autonomous Systems}},
volume = {5},
number = {1},
year = {2022},
doi = {10.1146/annurev-control-042920-020211},
URL = {https://doi.org/10.1146/annurev-control-042920-020211},
abstract = { The last half decade has seen a steep rise in the number of contributions on safe learning methods for real-world robotic deployments from both the control and reinforcement learning communities. This article provides a concise but holistic review of the recent advances made in using machine learning to achieve safe decision-making under uncertainties, with a focus on unifying the language and frameworks used in control theory and reinforcement learning research. It includes learning-based control approaches that safely improve performance by learning the uncertain dynamics, reinforcement learning approaches that encourage safety or robustness, and methods that can formally certify the safety of a learned control policy. As data- and learning-based robot control methods continue to gain traction, researchers must understand when and how to best leverage them in real-world scenarios where safety is imperative, such as when operating in close proximity to humans. We highlight some of the open challenges that will drive the field of robot learning in the coming years, and emphasize the need for realistic physics-based benchmarks to facilitate fair comparisons between control and reinforcement learning approaches. Expected final online publication date for the Annual Review of Control, Robotics, and Autonomous Systems, Volume 5 is May 2022. Please see http://www.annualreviews.org/page/journal/pubdates for revised estimates. }
} ![]() Bridging the model-reality gap with Lipschitz network adaptationS. Zhou, K. Pereida, W. Zhao, and A. P. SchoelligIEEE Robotics and Automation Letters, vol. 7, iss. 1, p. 642–649, 2022.
Bridging the model-reality gap with Lipschitz network adaptationS. Zhou, K. Pereida, W. Zhao, and A. P. SchoelligIEEE Robotics and Automation Letters, vol. 7, iss. 1, p. 642–649, 2022.
![]()
![]()
![]()
![]()
![]()
As robots venture into the real world, they are subject to unmodeled dynamics and disturbances. Traditional model-based control approaches have been proven successful in relatively static and known operating environments. However, when an accurate model of the robot is not available, model-based design can lead to suboptimal and even unsafe behaviour. In this work, we propose a method that bridges the model-reality gap and enables the application of model-based approaches even if dynamic uncertainties are present. In particular, we present a learning-based model reference adaptation approach that makes a robot system, with possibly uncertain dynamics, behave as a predefined reference model. In turn, the reference model can be used for model-based controller design. In contrast to typical model reference adaptation control approaches, we leverage the representative power of neural networks to capture highly nonlinear dynamics uncertainties and guarantee stability by encoding a certifying Lipschitz condition in the architectural design of a special type of neural network called the Lipschitz network. Our approach applies to a general class of nonlinear control-affine systems even when our prior knowledge about the true robot system is limited. We demonstrate our approach in flying inverted pendulum experiments, where an off-the-shelf quadrotor is challenged to balance an inverted pendulum while hovering or tracking circular trajectories.
@article{zhou-ral22,
author = {Siqi Zhou and Karime Pereida and Wenda Zhao and Angela P. Schoellig},
title = {Bridging the model-reality gap with {Lipschitz} network adaptation},
journal = {{IEEE Robotics and Automation Letters}},
year = {2022},
volume = {7},
number = {1},
pages = {642--649},
doi = {https://doi.org/10.1109/LRA.2021.3131698},
urllink = {https://arxiv.org/abs/2112.03756},
urlvideo = {http://tiny.cc/lipnet-pendulum},
abstract = {As robots venture into the real world, they are subject to unmodeled dynamics and disturbances. Traditional model-based control approaches have been proven successful in relatively static and known operating environments. However, when an accurate model of the robot is not available, model-based design can lead to suboptimal and even unsafe behaviour. In this work, we propose a method that bridges the model-reality gap and enables the application of model-based approaches even if dynamic uncertainties are present. In particular, we present a learning-based model reference adaptation approach that makes a robot system, with possibly uncertain dynamics, behave as a predefined reference model. In turn, the reference model can be used for model-based controller design. In contrast to typical model reference adaptation control approaches, we leverage the representative power of neural networks to capture highly nonlinear dynamics uncertainties and guarantee stability by encoding a certifying Lipschitz condition in the architectural design of a special type of neural network called the Lipschitz network. Our approach applies to a general class of nonlinear control-affine systems even when our prior knowledge about the true robot system is limited. We demonstrate our approach in flying inverted pendulum experiments, where an off-the-shelf quadrotor is challenged to balance an inverted pendulum while hovering or tracking circular trajectories.}
} ![]() Robust predictive output-feedback safety filter for uncertain nonlinear control systemsL. Brunke, S. Zhou, and A. P. Schoelligin Proc. of the IEEE Conference on Decision and Control (CDC), 2022, p. 3051–3058.
Robust predictive output-feedback safety filter for uncertain nonlinear control systemsL. Brunke, S. Zhou, and A. P. Schoelligin Proc. of the IEEE Conference on Decision and Control (CDC), 2022, p. 3051–3058.
![]()
![]()
@INPROCEEDINGS{brunke-cdc22,
author={Lukas Brunke and Siqi Zhou and Angela P. Schoellig},
booktitle={{Proc. of the IEEE Conference on Decision and Control (CDC)}},
title={Robust Predictive Output-Feedback Safety Filter for Uncertain Nonlinear Control Systems},
year={2022},
pages={3051--3058},
doi={10.1109/CDC51059.2022.9992834}
abstract={In real-world applications, we often require reliable decision making under dynamics uncertainties using noisy high-dimensional sensory data. Recently, we have seen an increasing number of learning-based control algorithms developed to address the challenge of decision making under dynamics uncertainties. These algorithms often make assumptions about the underlying unknown dynamics and, as a result, can provide safety guarantees. This is more challenging for other widely used learning-based decision making algorithms such as reinforcement learning. Furthermore, the majority of existing approaches assume access to state measurements, which can be restrictive in practice. In this paper, inspired by the literature on safety filters and robust output-feedback control, we present a robust predictive output-feedback safety filter (RPOF-SF) framework that provides safety certification to an arbitrary controller applied to an uncertain nonlinear control system. The proposed RPOF-SF combines a robustly stable observer that estimates the system state from noisy measurement data and a predictive safety filter that renders an arbitrary controller safe by (possibly) minimally modifying the controller input to guarantee safety. We show in theory that the proposed RPOF-SF guarantees constraint satisfaction despite disturbances applied to the system. We demonstrate the efficacy of the proposed RPOF-SF algorithm using an uncertain mass-spring-damper system.}
} ![]() Fusion of machine learning and MPC under uncertainty: what advances are on the horizon?A. Mesbah, K. P. Wabersich, A. P. Schoellig, M. N. Zeilinger, S. Lucia, T. A. Badgwell, and J. A. Paulsonin Proc. of the American Control Conference (ACC), 2022, p. 342–357.
Fusion of machine learning and MPC under uncertainty: what advances are on the horizon?A. Mesbah, K. P. Wabersich, A. P. Schoellig, M. N. Zeilinger, S. Lucia, T. A. Badgwell, and J. A. Paulsonin Proc. of the American Control Conference (ACC), 2022, p. 342–357.
![]()
![]()
![]()
This paper provides an overview of the recent research efforts on the integration of machine learning and model predictive control under uncertainty. The paper is organized as a collection of four major categories: learning models from system data and prior knowledge; learning control policy parameters from closed-loop performance data; learning efficient approximations of iterative online optimization from policy data; and learning optimal cost-to-go representations from closed-loop performance data. In addition to reviewing the relevant literature, the paper also offers perspectives for future research in each of these areas.
@INPROCEEDINGS{mesbah-acc22,
author={Ali Mesbah and Kim P. Wabersich and Angela P. Schoellig and Melanie N. Zeilinger and Sergio Lucia and Thomas A. Badgwell and Joel A. Paulson},
booktitle={{Proc. of the American Control Conference (ACC)}},
title={Fusion of Machine Learning and {MPC} under Uncertainty: What Advances Are on the Horizon?},
year={2022},
pages={342--357},
doi={10.23919/ACC53348.2022.9867643},
abstract = {This paper provides an overview of the recent research efforts on the integration of machine learning and model predictive control under uncertainty. The paper is organized as a collection of four major categories: learning models from system data and prior knowledge; learning control policy parameters from closed-loop performance data; learning efficient approximations of iterative online optimization from policy data; and learning optimal cost-to-go representations from closed-loop performance data. In addition to reviewing the relevant literature, the paper also offers perspectives for future research in each of these areas.}
} Barrier Bayesian linear regression: online learning of control barrier conditions for safety-critical control of uncertain systemsL. Brunke, S. Zhou, and A. P. Schoelligin Proc. of the Learning for Dynamics and Control Conference (L4DC), 2022, p. 881–892.
![]()
![]()
![]()
![]()
In this work, we consider the problem of designing a safety filter for a nonlinear uncertain control system. Our goal is to augment an arbitrary controller with a safety filter such that the overall closed-loop system is guaranteed to stay within a given state constraint set, referred to as being safe. For systems with known dynamics, control barrier functions (CBFs) provide a scalar condition for determining if a system is safe. For uncertain systems, robust or adaptive CBF certification approaches have been proposed. However, these approaches can be conservative or require the system to have a particular parametric structure. For more generic uncertain systems, machine learning approaches have been used to approximate the CBF condition. These works typically assume that the learning module is sufficiently trained prior to deployment. Safety during learning is not guaranteed. We propose a barrier Bayesian linear regression (BBLR) approach that guarantees safe online learning of the CBF condition for the true, uncertain system. We assume that the error between the nominal system and the true system is bounded and exploit the structure of the CBF condition. We show that our approach can safely expand the set of certifiable control inputs despite system and learning uncertainties. The effectiveness of our approach is demonstrated in simulation using a two-dimensional pendulum stabilization task.
@INPROCEEDINGS{brunke-l4dc22,
author={Lukas Brunke and Siqi Zhou and Angela P. Schoellig},
booktitle ={{Proc. of the Learning for Dynamics and Control Conference (L4DC)}},
title ={Barrier {Bayesian} Linear Regression: Online Learning of Control Barrier Conditions for Safety-Critical Control of Uncertain Systems},
year={2022},
pages ={881--892},
urllink = {https://proceedings.mlr.press/v168/brunke22a.html},
abstract = {In this work, we consider the problem of designing a safety filter for a nonlinear uncertain control system. Our goal is to augment an arbitrary controller with a safety filter such that the overall closed-loop system is guaranteed to stay within a given state constraint set, referred to as being safe. For systems with known dynamics, control barrier functions (CBFs) provide a scalar condition for determining if a system is safe. For uncertain systems, robust or adaptive CBF certification approaches have been proposed. However, these approaches can be conservative or require the system to have a particular parametric structure. For more generic uncertain systems, machine learning approaches have been used to approximate the CBF condition. These works typically assume that the learning module is sufficiently trained prior to deployment. Safety during learning is not guaranteed. We propose a barrier Bayesian linear regression (BBLR) approach that guarantees safe online learning of the CBF condition for the true, uncertain system. We assume that the error between the nominal system and the true system is bounded and exploit the structure of the CBF condition. We show that our approach can safely expand the set of certifiable control inputs despite system and learning uncertainties. The effectiveness of our approach is demonstrated in simulation using a two-dimensional pendulum stabilization task.}
} ![]() Robust adaptive model predictive control for guaranteed fast and accurate stabilization in the presence of model errorsK. Pereida, L. Brunke, and A. P. SchoelligInternational Journal of Robust and Nonlinear Control, vol. 31, iss. 18, p. 8750–8784, 2021.
Robust adaptive model predictive control for guaranteed fast and accurate stabilization in the presence of model errorsK. Pereida, L. Brunke, and A. P. SchoelligInternational Journal of Robust and Nonlinear Control, vol. 31, iss. 18, p. 8750–8784, 2021.
![]()
![]()
![]()
![]()
Numerous control applications, including robotic systems such as unmanned aerial vehicles or assistive robots, are expected to guarantee high performance despite being deployed in unknown and dynamic environments where they are subject to disturbances, unmodeled dynamics, and parametric uncertainties. The fast feedback of adaptive controllers makes them an effective approach for compensating for disturbances and unmodeled dynamics, but adaptive controllers seldom achieve high performance, nor do they guarantee state and input constraint satisfaction. In this article we propose a robust adaptive model predictive controller for guaranteed fast and accurate stabilization in the presence of model uncertainties. The proposed approach combines robust model predictive control (RMPC) with an underlying discrete-time adaptive controller. We refer to this combined controller as an RMPC- controller. The adaptive controller forces the system to behave close to a linear reference model despite the presence of parametric uncertainties. However, the true dynamics of the adaptive controlled system may deviate from the linear reference model. In this work we prove that this deviation is bounded and use it as the modeling error of the linear reference model. We combine adaptive control with an RMPC that leverages the linear reference model and the modeling error. We prove stability and recursive feasibility of the proposed RMPC-. Furthermore, we validate the feasibility, performance, and accuracy of the proposed RMPC- on a stabilization task in a numerical experiment. We demonstrate that the proposed RMPC- outperforms adaptive control, robust MPC, and other baseline controllers in all metrics.
@article{pereida-ijrnc21,
author = {Karime Pereida and Lukas Brunke and Angela P. Schoellig},
title = {Robust adaptive model predictive control for guaranteed fast and accurate stabilization in the presence of model errors},
journal = {{International Journal of Robust and Nonlinear Control}},
year = {2021},
volume = {31},
number = {18},
pages = {8750--8784},
doi = {https://doi.org/10.1002/rnc.5712},
urllink = {https://onlinelibrary.wiley.com/doi/abs/10.1002/rnc.5712},
abstract = {Numerous control applications, including robotic systems such as unmanned aerial vehicles or assistive robots, are expected to guarantee high performance despite being deployed in unknown and dynamic environments where they are subject to disturbances, unmodeled dynamics, and parametric uncertainties. The fast feedback of adaptive controllers makes them an effective approach for compensating for disturbances and unmodeled dynamics, but adaptive controllers seldom achieve high performance, nor do they guarantee state and input constraint satisfaction. In this article we propose a robust adaptive model predictive controller for guaranteed fast and accurate stabilization in the presence of model uncertainties. The proposed approach combines robust model predictive control (RMPC) with an underlying discrete-time adaptive controller. We refer to this combined controller as an RMPC- controller. The adaptive controller forces the system to behave close to a linear reference model despite the presence of parametric uncertainties. However, the true dynamics of the adaptive controlled system may deviate from the linear reference model. In this work we prove that this deviation is bounded and use it as the modeling error of the linear reference model. We combine adaptive control with an RMPC that leverages the linear reference model and the modeling error. We prove stability and recursive feasibility of the proposed RMPC-. Furthermore, we validate the feasibility, performance, and accuracy of the proposed RMPC- on a stabilization task in a numerical experiment. We demonstrate that the proposed RMPC- outperforms adaptive control, robust MPC, and other baseline controllers in all metrics.}
} ![]() RLO-MPC: robust learning-based output feedback MPC for improving the performance of uncertain systems in iterative tasksL. Brunke, S. Zhou, and A. P. Schoelligin Proc. of the IEEE Conference on Decision and Control (CDC), 2021, pp. 2183-2190.
RLO-MPC: robust learning-based output feedback MPC for improving the performance of uncertain systems in iterative tasksL. Brunke, S. Zhou, and A. P. Schoelligin Proc. of the IEEE Conference on Decision and Control (CDC), 2021, pp. 2183-2190.
![]()
![]()
![]()
![]()
In this work we address the problem of performing a repetitive task when we have uncertain observations and dynamics. We formulate this problem as an iterative infinite horizon optimal control problem with output feedback. Previously, this problem was solved for linear time-invariant (LTI) system for the case when noisy full-state measurements are available using a robust iterative learning control framework, which we refer to as robust learning-based model predictive control (RL-MPC). However, this work does not apply to the case when only noisy observations of part of the state are available. This limits the applicability of current approaches in practice: First, in practical applications we typically do not have access to the full state. Second, uncertainties in the observations, when not accounted for, can lead to instability and constraint violations. To overcome these limitations, we propose a combination of RL-MPC with robust output feedback model predictive control, named robust learning-based output feedback model predictive control (RLO-MPC). We show recursive feasibility and stability, and prove theoretical guarantees on the performance over iterations. We validate the proposed approach with a numerical example in simulation and a quadrotor stabilization task in experiments.
@INPROCEEDINGS{brunke-cdc21,
author={Lukas Brunke and Siqi Zhou and Angela P. Schoellig},
booktitle={{Proc. of the IEEE Conference on Decision and Control (CDC)}},
title={{RLO-MPC}: Robust Learning-Based Output Feedback {MPC} for Improving the Performance of Uncertain Systems in Iterative Tasks},
year={2021},
pages={2183-2190},
urlvideo = {https://youtu.be/xJ8xFKp3cAo},
doi={10.1109/CDC45484.2021.9682940},
abstract = {In this work we address the problem of performing a repetitive task when we have uncertain observations and dynamics. We formulate this problem as an iterative infinite horizon optimal control problem with output feedback. Previously, this problem was solved for linear time-invariant (LTI) system for the case when noisy full-state measurements are available using a robust iterative learning control framework, which we refer to as robust learning-based model predictive control (RL-MPC). However, this work does not apply to the case when only noisy observations of part of the state are available. This limits the applicability of current approaches in practice: First, in practical applications we typically do not have access to the full state. Second, uncertainties in the observations, when not accounted for, can lead to instability and constraint violations. To overcome these limitations, we propose a combination of RL-MPC with robust output feedback model predictive control, named robust learning-based output feedback model predictive control (RLO-MPC). We show recursive feasibility and stability, and prove theoretical guarantees on the performance over iterations. We validate the proposed approach with a numerical example in simulation and a quadrotor stabilization task in experiments.}
} ![]() Safe and robust learning control with Gaussian processesF. Berkenkamp and A. P. Schoelligin Proc. of the European Control Conference (ECC), 2015, p. 2501–2506.
Safe and robust learning control with Gaussian processesF. Berkenkamp and A. P. Schoelligin Proc. of the European Control Conference (ECC), 2015, p. 2501–2506.
![]()
![]()
![]()
![]()
![]()
This paper introduces a learning-based robust control algorithm that provides robust stability and performance guarantees during learning. The approach uses Gaussian process (GP) regression based on data gathered during operation to update an initial model of the system and to gradually decrease the uncertainty related to this model. Embedding this data-based update scheme in a robust control framework guarantees stability during the learning process. Traditional robust control approaches have not considered online adaptation of the model and its uncertainty before. As a result, their controllers do not improve performance during operation. Typical machine learning algorithms that have achieved similar high-performance behavior by adapting the model and controller online do not provide the guarantees presented in this paper. In particular, this paper considers a stabilization task, linearizes the nonlinear, GP-based model around a desired operating point, and solves a convex optimization problem to obtain a linear robust controller. The resulting performance improvements due to the learning-based controller are demonstrated in experiments on a quadrotor vehicle.
@INPROCEEDINGS{berkenkamp-ecc15,
author = {Felix Berkenkamp and Angela P. Schoellig},
title = {Safe and robust learning control with {G}aussian processes},
booktitle = {{Proc. of the European Control Conference (ECC)}},
pages = {2501--2506},
year = {2015},
doi = {10.1109/ECC.2015.7330913},
urlvideo={https://youtu.be/YqhLnCm0KXY?list=PLC12E387419CEAFF2},
urlslides={../../wp-content/papercite-data/slides/berkenkamp-ecc15-slides.pdf},
abstract = {This paper introduces a learning-based robust control algorithm that provides robust stability and performance guarantees during learning. The approach uses Gaussian process (GP) regression based on data gathered during operation to update an initial model of the system and to gradually decrease the uncertainty related to this model. Embedding this data-based update scheme in a robust control framework guarantees stability during the learning process. Traditional robust control approaches have not considered online adaptation of the model and its uncertainty before. As a result, their controllers do not improve performance during operation. Typical machine learning algorithms that have achieved similar high-performance behavior by adapting the model and controller online do not provide the guarantees presented in this paper. In particular, this paper considers a stabilization task, linearizes the nonlinear, GP-based model around a desired operating point, and solves a convex optimization problem to obtain a linear robust controller. The resulting performance improvements due to the learning-based controller are demonstrated in experiments on a quadrotor vehicle.}
} ![]() Conservative to confident: treating uncertainty robustly within learning-based controlC. J. Ostafew, A. P. Schoellig, and T. D. Barfootin Proc. of the IEEE International Conference on Robotics and Automation (ICRA), 2015, p. 421–427.
Conservative to confident: treating uncertainty robustly within learning-based controlC. J. Ostafew, A. P. Schoellig, and T. D. Barfootin Proc. of the IEEE International Conference on Robotics and Automation (ICRA), 2015, p. 421–427.
![]()
![]()
![]()
Robust control maintains stability and performance for a fixed amount of model uncertainty but can be conservative since the model is not updated online. Learning- based control, on the other hand, uses data to improve the model over time but is not typically guaranteed to be robust throughout the process. This paper proposes a novel combination of both ideas: a robust Min-Max Learning-Based Nonlinear Model Predictive Control (MM-LB-NMPC) algorithm. Based on an existing LB-NMPC algorithm, we present an efficient and robust extension, altering the NMPC performance objective to optimize for the worst-case scenario. The algorithm uses a simple a priori vehicle model and a learned disturbance model. Disturbances are modelled as a Gaussian Process (GP) based on experience collected during previous trials as a function of system state, input, and other relevant variables. Nominal state sequences are predicted using an Unscented Transform and worst-case scenarios are defined as sequences bounding the 3σ confidence region. Localization for the controller is provided by an on-board, vision-based mapping and navigation system enabling operation in large-scale, GPS-denied environments. The paper presents experimental results from testing on a 50 kg skid-steered robot executing a path-tracking task. The results show reductions in maximum lateral and heading path-tracking errors by up to 30% and a clear transition from robust control when the model uncertainty is high to optimal control when model uncertainty is reduced.
@INPROCEEDINGS{ostafew-icra15,
author = {Chris J. Ostafew and Angela P. Schoellig and Timothy D. Barfoot},
title = {Conservative to confident: treating uncertainty robustly within learning-based control},
booktitle = {{Proc. of the IEEE International Conference on Robotics and Automation (ICRA)}},
pages = {421--427},
year = {2015},
doi = {10.1109/ICRA.2015.7139033},
note = {},
abstract = {Robust control maintains stability and performance for a fixed amount of model uncertainty but can be conservative since the model is not updated online. Learning- based control, on the other hand, uses data to improve the model over time but is not typically guaranteed to be robust throughout the process. This paper proposes a novel combination of both ideas: a robust Min-Max Learning-Based Nonlinear Model Predictive Control (MM-LB-NMPC) algorithm. Based on an existing LB-NMPC algorithm, we present an efficient and robust extension, altering the NMPC performance objective to optimize for the worst-case scenario. The algorithm uses a simple a priori vehicle model and a learned disturbance model. Disturbances are modelled as a Gaussian Process (GP) based on experience collected during previous trials as a function of system state, input, and other relevant variables. Nominal state sequences are predicted using an Unscented Transform and worst-case scenarios are defined as sequences bounding the 3σ confidence region. Localization for the controller is provided by an on-board, vision-based mapping and navigation system enabling operation in large-scale, GPS-denied environments. The paper presents experimental results from testing on a 50 kg skid-steered robot executing a path-tracking task. The results show reductions in maximum lateral and heading path-tracking errors by up to 30% and a clear transition from robust control when the model uncertainty is high to optimal control when model uncertainty is reduced.}
}Learning of Feed-Forward Corrections
High-accuracy trajectory tracking is critical to many robotic applications, including search and rescue, advanced manufacturing, and industrial inspection, to name a few. Yet the unmodeled dynamics and parametric uncertainties of operating in such complex environments make it difficult to design controllers that are capable of accurately tracking arbitrary, feasible trajectories from the first attempt (i.e., impromptu trajectory tracking). This article proposes a platform-independent, learning-based ‘‘add-on’’ module to enhance the tracking performance of black-box control systems in impromptu tracking tasks. Our approach is to pre-cascade a deep neural network (DNN) to a stabilized baseline control system, in order to establish an identity mapping from the desired output to the actual output. Previous research involving quadrotors showed that, for 30 arbitrary hand-drawn trajectories, the DNN-enhancement control architecture reduces tracking errors by 43\% on average, as compared with the baseline controller. In this article, we provide a platform-independent formulation and practical design guidelines for the DNN-enhancement approach. In particular, we: (1) characterize the underlying function of the DNN module; (2) identify necessary conditions for the approach to be effective; (3) provide theoretical insights into the stability of the overall DNN-enhancement control architecture; (4) derive a condition that supports dataefficient training of the DNN module; and (5) compare the novel theory-driven DNN design with the prior trial-and-error design using detailed quadrotor experiments. We show that, as compared with the prior trial-and-error design, the novel theory-driven design allows us to reduce the input dimension of the DNN by two thirds while achieving similar tracking performance.
@article{zhou-ijrr20,
title = {Deep neural networks as add-on modules for enhancing robot performance in impromptu trajectory tracking},
author = {Siqi Zhou and Mohamed K. Helwa and Angela P. Schoellig},
journal = {{The International Journal of Robotics Research}},
year = {2020},
volume = {0},
number = {0},
pages = {1--22},
doi = {10.1177/0278364920953902},
urllink = {https://doi.org/10.1177/0278364920953902},
urlvideo = {https://youtu.be/K-DrZGFvpN4},
abstract = {High-accuracy trajectory tracking is critical to many robotic applications, including search and rescue, advanced manufacturing, and industrial inspection, to name a few. Yet the unmodeled dynamics and parametric uncertainties of operating in such complex environments make it difficult to design controllers that are capable of accurately tracking arbitrary, feasible trajectories from the first attempt (i.e., impromptu trajectory tracking). This article proposes a platform-independent,
learning-based ‘‘add-on’’ module to enhance the tracking performance of black-box control systems in impromptu tracking tasks. Our approach is to pre-cascade a deep neural network (DNN) to a stabilized baseline control system, in order to establish an identity mapping from the desired output to the actual output. Previous research involving quadrotors showed that, for 30 arbitrary hand-drawn trajectories, the DNN-enhancement control architecture reduces tracking errors by 43\% on average, as compared with the baseline controller. In this article, we provide a platform-independent formulation and practical design guidelines for the DNN-enhancement approach. In particular, we: (1) characterize the underlying function of the DNN module; (2) identify necessary conditions for the approach to be effective; (3) provide theoretical insights into the stability of the overall DNN-enhancement control architecture; (4) derive a condition that supports dataefficient training of the DNN module; and (5) compare the novel theory-driven DNN design with the prior trial-and-error design using detailed quadrotor experiments. We show that, as compared with the prior trial-and-error design, the novel theory-driven design allows us to reduce the input dimension of the DNN by two thirds while achieving similar tracking performance.}
} ![]() Design of norm-optimal iterative learning controllers: the effect of an iteration-domain Kalman filter for disturbance estimationN. Degen and A. P. Schoelligin Proc. of the IEEE Conference on Decision and Control (CDC), 2014, pp. 3590-3596.
Design of norm-optimal iterative learning controllers: the effect of an iteration-domain Kalman filter for disturbance estimationN. Degen and A. P. Schoelligin Proc. of the IEEE Conference on Decision and Control (CDC), 2014, pp. 3590-3596.
![]()
![]()
![]()
![]()
Iterative learning control (ILC) has proven to be an effective method for improving the performance of repetitive control tasks. This paper revisits two optimization-based ILC algorithms: (i) the widely used quadratic-criterion ILC law (QILC) and (ii) an estimation-based ILC law using an iteration-domain Kalman filter (K-ILC). The goal of this paper is to analytically compare both algorithms and to highlight the advantages of the Kalman-filter-enhanced algorithm. We first show that for an iteration-constant estimation gain and an appropriate choice of learning parameters both algorithms are identical. We then show that the estimation-enhanced algorithm with its iteration-varying optimal Kalman gains can achieve both fast initial convergence and good noise rejection by (optimally) adapting the learning update rule over the course of an experiment. We conclude that the clear separation of disturbance estimation and input update of the K-ILC algorithm provides an intuitive architecture to design learning schemes that achieve both low noise sensitivity and fast convergence. To benchmark the algorithms we use a simulation of a single-input, single-output mass-spring-damper system.
@INPROCEEDINGS{degen-cdc14,
author = {Nicolas Degen and Angela P. Schoellig},
title = {Design of norm-optimal iterative learning controllers: the effect of an iteration-domain {K}alman filter for disturbance estimation},
booktitle = {{Proc. of the IEEE Conference on Decision and Control (CDC)}},
pages = {3590-3596},
year = {2014},
doi = {10.1109/CDC.2014.7039947},
urlslides = {../../wp-content/papercite-data/slides/degen-cdc14-slides.pdf},
abstract = {Iterative learning control (ILC) has proven to be an effective method for improving the performance of repetitive control tasks. This paper revisits two optimization-based ILC algorithms: (i) the widely used quadratic-criterion ILC law (QILC) and (ii) an estimation-based ILC law using an iteration-domain Kalman filter (K-ILC). The goal of this paper is to analytically compare both algorithms and to highlight the advantages of the Kalman-filter-enhanced algorithm. We first show that for an iteration-constant estimation gain and an appropriate choice of learning parameters both algorithms are identical. We then show that the estimation-enhanced algorithm with its iteration-varying optimal Kalman gains can achieve both fast initial convergence and good noise rejection by (optimally) adapting the learning update rule over the course of an experiment. We conclude that the clear separation of disturbance estimation and input update of the K-ILC algorithm provides an intuitive architecture to design learning schemes that achieve both low noise sensitivity and fast convergence. To benchmark the algorithms we use a simulation of a single-input, single-output mass-spring-damper system.}
} ![]() Speed daemon: experience-based mobile robot speed schedulingC. J. Ostafew, A. P. Schoellig, T. D. Barfoot, and J. Collierin Proc. of the International Conference on Computer and Robot Vision (CRV), 2014, pp. 56-62. Best Robotics Paper Award.
Speed daemon: experience-based mobile robot speed schedulingC. J. Ostafew, A. P. Schoellig, T. D. Barfoot, and J. Collierin Proc. of the International Conference on Computer and Robot Vision (CRV), 2014, pp. 56-62. Best Robotics Paper Award.
![]()
![]()
![]()
![]()
A time-optimal speed schedule results in a mobile robot driving along a planned path at or near the limits of the robot’s capability. However, deriving models to predict the effect of increased speed can be very difficult. In this paper, we present a speed scheduler that uses previous experience, instead of complex models, to generate time-optimal speed schedules. The algorithm is designed for a vision-based, path-repeating mobile robot and uses experience to ensure reliable localization, low path-tracking errors, and realizable control inputs while maximizing the speed along the path. To our knowledge, this is the first speed scheduler to incorporate experience from previous path traversals in order to address system constraints. The proposed speed scheduler was tested in over 4 km of path traversals in outdoor terrain using a large Ackermann-steered robot travelling between 0.5 m/s and 2.0 m/s. The approach to speed scheduling is shown to generate fast speed schedules while remaining within the limits of the robot’s capability.
@INPROCEEDINGS{ostafew-crv14,
author = {Chris J. Ostafew and Angela P. Schoellig and Timothy D. Barfoot and J. Collier},
title = {Speed daemon: experience-based mobile robot speed scheduling},
booktitle = {{Proc. of the International Conference on Computer and Robot Vision (CRV)}},
pages = {56-62},
year = {2014},
doi = {10.1109/CRV.2014.16},
urlvideo = {https://youtu.be/Pu3_F6k6Fa4?list=PLC12E387419CEAFF2},
abstract = {A time-optimal speed schedule results in a mobile robot driving along a planned path at or near the limits of the robot's capability. However, deriving models to predict the effect of increased speed can be very difficult. In this paper, we present a speed scheduler that uses previous experience, instead of complex models, to generate time-optimal speed schedules. The algorithm is designed for a vision-based, path-repeating mobile robot and uses experience to ensure reliable localization, low path-tracking errors, and realizable control inputs while maximizing the speed along the path. To our knowledge, this is the first speed scheduler to incorporate experience from previous path traversals in order to address system constraints. The proposed speed scheduler was tested in over 4 km of path traversals in outdoor terrain using a large Ackermann-steered robot travelling between 0.5 m/s and 2.0 m/s. The approach to speed scheduling is shown to generate fast speed schedules while remaining within the limits of the robot's capability.},
note = {Best Robotics Paper Award}
} ![]() Visual teach and repeat, repeat, repeat: iterative learning control to improve mobile robot path tracking in challenging outdoor environmentsC. J. Ostafew, A. P. Schoellig, and T. D. Barfootin Proc. of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2013, pp. 176-181.
Visual teach and repeat, repeat, repeat: iterative learning control to improve mobile robot path tracking in challenging outdoor environmentsC. J. Ostafew, A. P. Schoellig, and T. D. Barfootin Proc. of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2013, pp. 176-181.
![]()
![]()
![]()
![]()
This paper presents a path-repeating, mobile robot controller that combines a feedforward, proportional Iterative Learning Control (ILC) algorithm with a feedback-linearized path-tracking controller to reduce path-tracking errors over repeated traverses along a reference path. Localization for the controller is provided by an on-board, vision-based mapping and navigation system enabling operation in large-scale, GPS-denied, extreme environments. The paper presents experimental results including over 600 m of travel by a four-wheeled, 50 kg robot travelling through challenging terrain including steep hills and sandy turns and by a six-wheeled, 160 kg robot at gradually-increased speeds up to three times faster than the nominal, safe speed. In the absence of a global localization system, ILC is demonstrated to reduce path-tracking errors caused by unmodelled robot dynamics and terrain challenges.
@INPROCEEDINGS{ostafew-iros13,
author = {Chris J. Ostafew and Angela P. Schoellig and Timothy D. Barfoot},
title = {Visual teach and repeat, repeat, repeat: Iterative learning control to improve mobile robot path tracking in challenging outdoor environments},
booktitle = {{Proc. of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}},
pages = {176-181},
year = {2013},
doi = {10.1109/IROS.2013.6696350},
urlvideo = {https://youtu.be/08_d1HSPADA?list=PLC12E387419CEAFF2},
abstract = {This paper presents a path-repeating, mobile robot controller that combines a feedforward, proportional Iterative Learning Control (ILC) algorithm with a feedback-linearized path-tracking controller to reduce path-tracking errors over repeated traverses along a reference path. Localization for the controller is provided by an on-board, vision-based mapping and navigation system enabling operation in large-scale, GPS-denied, extreme environments. The paper presents experimental results including over 600 m of travel by a four-wheeled, 50 kg robot travelling through challenging terrain including steep hills and sandy turns and by a six-wheeled, 160 kg robot at gradually-increased speeds up to three times faster than the nominal, safe speed. In the absence of a global localization system, ILC is demonstrated to reduce path-tracking errors caused by unmodelled robot dynamics and terrain challenges.}
} ![]() Improving tracking performance by learning from past dataA. P. SchoelligPhD Thesis, Diss. ETH No. 20593, Institute for Dynamic Systems and Control, ETH Zurich, Switzerland, 2013. Awards: ETH Medal, Dimitris N. Chorafas Foundation Prize.
Improving tracking performance by learning from past dataA. P. SchoelligPhD Thesis, Diss. ETH No. 20593, Institute for Dynamic Systems and Control, ETH Zurich, Switzerland, 2013. Awards: ETH Medal, Dimitris N. Chorafas Foundation Prize.
![]()
![]()
![]()
![]()
![]()
![]()
@PHDTHESIS{schoellig-eth13,
author = {Angela P. Schoellig},
title = {Improving tracking performance by learning from past data},
school = {Diss. ETH No. 20593, Institute for Dynamic Systems and Control, ETH Zurich},
doi = {10.3929/ethz-a-009758916},
year = {2013},
address = {Switzerland},
urlabstract = {../../wp-content/papercite-data/pdf/schoellig-eth13-abstract.pdf},
urlslides = {../../wp-content/papercite-data/slides/schoellig-eth13-slides.pdf},
urlvideo = {https://youtu.be/zHTCsSkmADo?list=PLC12E387419CEAFF2},
urlvideo2 = {https://youtu.be/7r281vgfotg?list=PLD6AAACCBFFE64AC5},
note = {Awards: ETH Medal, Dimitris N. Chorafas Foundation Prize}
} ![]() Optimization-based iterative learning for precise quadrocopter trajectory trackingA. P. Schoellig, F. L. Mueller, and R. D’AndreaAutonomous Robots, vol. 33, iss. 1-2, pp. 103-127, 2012.
Optimization-based iterative learning for precise quadrocopter trajectory trackingA. P. Schoellig, F. L. Mueller, and R. D’AndreaAutonomous Robots, vol. 33, iss. 1-2, pp. 103-127, 2012.
![]()
![]()
![]()
![]()
Current control systems regulate the behavior of dynamic systems by reacting to noise and unexpected disturbances as they occur. To improve the performance of such control systems, experience from iterative executions can be used to anticipate recurring disturbances and proactively compensate for them. This paper presents an algorithm that exploits data from previous repetitions in order to learn to precisely follow a predefined trajectory. We adapt the feed-forward input signal to the system with the goal of achieving high tracking performance – even under the presence of model errors and other recurring disturbances. The approach is based on a dynamics model that captures the essential features of the system and that explicitly takes system input and state constraints into account. We combine traditional optimal filtering methods with state-of-the-art optimization techniques in order to obtain an effective and computationally efficient learning strategy that updates the feed-forward input signal according to a customizable learning objective. It is possible to define a termination condition that stops an execution early if the deviation from the nominal trajectory exceeds a given bound. This allows for a safe learning that gradually extends the time horizon of the trajectory. We developed a framework for generating arbitrary flight trajectories and for applying the algorithm to highly maneuverable autonomous quadrotor vehicles in the ETH Flying Machine Arena testbed. Experimental results are discussed for selected trajectories and different learning algorithm parameters.
@ARTICLE{schoellig-auro12,
author = {Angela P. Schoellig and Fabian L. Mueller and Raffaello D'Andrea},
title = {Optimization-based iterative learning for precise quadrocopter trajectory tracking},
journal = {{Autonomous Robots}},
volume = {33},
number = {1-2},
pages = {103-127},
year = {2012},
doi = {10.1007/s10514-012-9283-2},
urlvideo={http://youtu.be/goVuP5TJIUU?list=PLC12E387419CEAFF2},
abstract = {Current control systems regulate the behavior of dynamic systems by reacting to noise and unexpected disturbances as they occur. To improve the performance of such control systems, experience from iterative executions can be used to anticipate recurring disturbances and proactively compensate for them. This paper presents an algorithm that exploits data from previous repetitions in order to learn to precisely follow a predefined trajectory. We adapt the feed-forward input signal to the system with the goal of achieving high tracking performance - even under the presence of model errors and other recurring disturbances. The approach is based on a dynamics model that captures the essential features of the system and that explicitly takes system input and state constraints into account. We combine traditional optimal filtering methods with state-of-the-art optimization techniques in order to obtain an effective and computationally efficient learning strategy that updates the feed-forward input signal according to a customizable learning objective. It is possible to define a termination condition that stops an execution early if the deviation from the nominal trajectory exceeds a given bound. This allows for a safe learning that gradually extends the time horizon of the trajectory. We developed a framework for generating arbitrary flight trajectories and for applying the algorithm to highly maneuverable autonomous quadrotor vehicles in the ETH Flying Machine Arena testbed. Experimental results are discussed for selected trajectories and different learning algorithm parameters.}
} ![]() Iterative learning of feed-forward corrections for high-performance trackingF. L. Mueller, A. P. Schoellig, and R. D’Andreain Proc. of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2012, pp. 3276-3281.
Iterative learning of feed-forward corrections for high-performance trackingF. L. Mueller, A. P. Schoellig, and R. D’Andreain Proc. of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2012, pp. 3276-3281.
![]()
![]()
![]()
![]()
![]()
We revisit a recently developed iterative learning algorithm that enables systems to learn from a repeated operation with the goal of achieving high tracking performance of a given trajectory. The learning scheme is based on a coarse dynamics model of the system and uses past measurements to iteratively adapt the feed-forward input signal to the system. The novelty of this work is an identification routine that uses a numerical simulation of the system dynamics to extract the required model information. This allows the learning algorithm to be applied to any dynamic system for which a dynamics simulation is available (including systems with underlying feedback loops). The proposed learning algorithm is applied to a quadrocopter system that is guided by a trajectory-following controller. With the identification routine, we are able to extend our previous learning results to three-dimensional quadrocopter motions and achieve significantly higher tracking accuracy due to the underlying feedback control, which accounts for non-repetitive noise.
@INPROCEEDINGS{mueller-iros12,
author = {Fabian L. Mueller and Angela P. Schoellig and Raffaello D'Andrea},
title = {Iterative learning of feed-forward corrections for high-performance tracking},
booktitle = {{Proc. of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}},
pages = {3276-3281},
year = {2012},
doi = {10.1109/IROS.2012.6385647},
urlvideo = {https://youtu.be/zHTCsSkmADo?list=PLC12E387419CEAFF2},
urlslides = {../../wp-content/papercite-data/slides/mueller-iros12-slides.pdf},
abstract = {We revisit a recently developed iterative learning algorithm that enables systems to learn from a repeated operation with the goal of achieving high tracking performance of a given trajectory. The learning scheme is based on a coarse dynamics model of the system and uses past measurements to iteratively adapt the feed-forward input signal to the system. The novelty of this work is an identification routine that uses a numerical simulation of the system dynamics to extract the required model information. This allows the learning algorithm to be applied to any dynamic system for which a dynamics simulation is available (including systems with underlying feedback loops). The proposed learning algorithm is applied to a quadrocopter system that is guided by a trajectory-following controller. With the identification routine, we are able to extend our previous learning results to three-dimensional quadrocopter motions and achieve significantly higher tracking accuracy due to the underlying feedback control, which accounts for non-repetitive noise.}
} ![]() Feed-forward parameter identification for precise periodic quadrocopter motionsA. P. Schoellig, C. Wiltsche, and R. D’Andreain Proc. of the American Control Conference (ACC), 2012, pp. 4313-4318.
Feed-forward parameter identification for precise periodic quadrocopter motionsA. P. Schoellig, C. Wiltsche, and R. D’Andreain Proc. of the American Control Conference (ACC), 2012, pp. 4313-4318.
![]()
![]()
![]()
![]()
![]()
This paper presents an approach for precisely tracking periodic trajectories with a quadrocopter. In order to improve temporal and spatial tracking performance, we propose a feed-forward strategy that adapts the motion parameters sent to the vehicle controller. The motion parameters are either adjusted on the fly or, in order to avoid initial transients, identified prior to the flight performance. We outline an identification scheme that tunes parameters for a large class of periodic motions, and requires only a small number of identification experiments prior to flight. This reduced identification is based on analysis and experiments showing that the quadrocopter’s closed-loop dynamics can be approximated by three directionally decoupled linear systems. We show the effectiveness of this approach by performing a sequence of periodic motions on real quadrocopters using the tuned parameters obtained by the reduced identification.
@INPROCEEDINGS{schoellig-acc12,
author = {Angela P. Schoellig and Clemens Wiltsche and Raffaello D'Andrea},
title = {Feed-forward parameter identification for precise periodic quadrocopter motions},
booktitle = {{Proc. of the American Control Conference (ACC)}},
pages = {4313-4318},
year = {2012},
doi = {10.1109/ACC.2012.6315248},
urlvideo = {http://tiny.cc/MusicInMotion},
urlslides = {../../wp-content/papercite-data/slides/schoellig-acc12-slides.pdf},
abstract = {This paper presents an approach for precisely tracking periodic trajectories with a quadrocopter. In order to improve temporal and spatial tracking performance, we propose a feed-forward strategy that adapts the motion parameters sent to the vehicle controller. The motion parameters are either adjusted on the fly or, in order to avoid initial transients, identified prior to the flight performance. We outline an identification scheme that tunes parameters for a large class of periodic motions, and requires only a small number of identification experiments prior to flight. This reduced identification is based on analysis and experiments showing that the quadrocopter's closed-loop dynamics can be approximated by three directionally decoupled linear systems. We show the effectiveness of this approach by performing a sequence of periodic motions on real quadrocopters using the tuned parameters obtained by the reduced identification.}
} Optimization-based iterative learning control for trajectory trackingA. P. Schoellig and R. D’Andreain Proc. of the European Control Conference (ECC), 2009, pp. 1505-1510.
![]()
![]()
![]()
![]()
![]()
![]()
In this paper, an optimization-based iterative learning control approach is presented. Given a desired trajectory to be followed, the proposed learning algorithm improves the system performance from trial to trial by exploiting the experience gained from previous repetitions. Taking advantage of the a-priori knowledge about the systems dominating dynamics, a data-based update rule is derived which adapts the feedforward input signal after each trial. By combining traditional model-based optimal filtering methods with state-of-the-art optimization techniques such as convex programming, an effective and computationally highly efficient learning strategy is obtained. Moreover, the derived formalism allows for the direct treatment of input and state constraints. Different (nonlinear) performance objectives can be specified defining the overall learning behavior. Finally, the proposed algorithm is successfully applied to the benchmark problem of swinging up a pendulum using open-loop control only.
@INPROCEEDINGS{schoellig-ecc09,
author = {Angela P. Schoellig and Raffaello D'Andrea},
title = {Optimization-based iterative learning control for trajectory tracking},
booktitle = {{Proc. of the European Control Conference (ECC)}},
pages = {1505-1510},
year = {2009},
urlslides = {../../wp-content/papercite-data/slides/schoellig-ecc09-slides.pdf},
urllink = {http://ieeexplore.ieee.org/xpl/articleDetails.jsp?reload=true&arnumber=7074619},
urlvideo = {https://youtu.be/W2gCn6aAwz4?list=PLC12E387419CEAFF2},
abstract = {In this paper, an optimization-based iterative learning control approach is presented. Given a desired trajectory to be followed, the proposed learning algorithm improves the system performance from trial to trial by exploiting the experience gained from previous repetitions. Taking advantage of the a-priori knowledge about the systems dominating dynamics, a data-based update rule is derived which adapts the feedforward input signal after each trial. By combining traditional model-based optimal filtering methods with state-of-the-art optimization techniques such as convex programming, an effective and computationally highly efficient learning strategy is obtained. Moreover, the derived formalism allows for the direct treatment of input and state constraints. Different (nonlinear) performance objectives can be specified defining the overall learning behavior. Finally, the proposed algorithm is successfully applied to the benchmark problem of swinging up a pendulum using open-loop control only.}
} Learning through experience – Optimizing performance by repetitionA. P. Schoellig and R. D’AndreaAbstract and Poster, in Proc. of the Robotics Challenges for Machine Learning Workshop at the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2008.
![]()
![]()
![]()
![]()
![]()
![]()
The goal of our research is to develop a strategy which enables a system, executing the same task multiple times, to use the knowledge of the previous trials to learn more about its own dynamics and enhance its future performance. Our approach, which falls in the field of iterative learning control, combines methods from both areas, traditional model-based estimation and control and purely data-based learning.
@MISC{schoellig-iros08,
author = {Angela P. Schoellig and Raffaello D'Andrea},
title = {Learning through experience -- {O}ptimizing performance by repetition},
howpublished = {Abstract and Poster, in Proc. of the Robotics Challenges for Machine Learning Workshop at the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
year = {2008},
urlvideo = {https://youtu.be/W2gCn6aAwz4?list=PLC12E387419CEAFF2},
urlslides = {../../wp-content/papercite-data/slides/schoellig-iros08-slides.pdf},
urllink = {http://www.learning-robots.de/pmwiki.php/TC/IROS2008},
abstract = {The goal of our research is to develop a strategy which enables a system, executing the same task multiple times, to use the knowledge of the previous trials to learn more about its own dynamics and enhance its future performance. Our approach, which falls in the field of iterative learning control, combines methods from both areas, traditional model-based estimation and control and purely data-based learning.},
}Gradient-Based Learning
We describe a simple and intuitive policy gradient method for improving parametrized quadrocopter multi-flips by combining iterative experiments with information from a first-principles model. We start by formulating an N-flip maneuver as a five-step primitive with five adjustable parameters. Optimization using a low-order first-principles 2D vertical plane model of the quadrocopter yields an initial set of parameters and a corrective matrix. The maneuver is then repeatedly performed with the vehicle. At each iteration the state error at the end of the primitive is used to update the maneuver parameters via a gradient adjustment. The method is demonstrated at the ETH Zurich Flying Machine Arena testbed on quadrotor helicopters performing and improving on flips, double flips and triple flips.
@INPROCEEDINGS{lupashin-icra10,
author = {Sergei Lupashin and Angela P. Schoellig and Michael Sherback and Raffaello D'Andrea},
title = {A simple learning strategy for high-speed quadrocopter multi-flips},
booktitle = {{Proc. of the IEEE International Conference on Robotics and Automation (ICRA)}},
pages = {1642-1648},
year = {2010},
doi = {10.1109/ROBOT.2010.5509452},
urlvideo = {https://youtu.be/bWExDW9J9sA?list=PLC12E387419CEAFF2},
abstract = {We describe a simple and intuitive policy gradient method for improving parametrized quadrocopter multi-flips by combining iterative experiments with information from a first-principles model. We start by formulating an N-flip maneuver as a five-step primitive with five adjustable parameters. Optimization using a low-order first-principles 2D vertical plane model of the quadrocopter yields an initial set of parameters and a corrective matrix. The maneuver is then repeatedly performed with the vehicle. At each iteration the state error at the end of the primitive is used to update the maneuver parameters via a gradient adjustment. The method is demonstrated at the ETH Zurich Flying Machine Arena testbed on quadrotor helicopters performing and improving on flips, double flips and triple flips.}
}High-Performance Control
In this paper, we present a modular framework for solving a motion planning problem among a group of robots. The proposed framework utilizes a finite set of low-level motion primitives to generate motions in a gridded workspace. The constraints on allowable sequences of motion primitives are formalized through a maneuver automaton . At the high level, a control policy determines which motion primitive is executed in each box of the gridded workspace. We state general conditions on motion primitives to obtain provably correct behavior so that a library of safe-by-design motion primitives can be designed. The overall framework yields a highly robust design by utilizing feedback strategies at both the low and high levels. We provide specific designs for motion primitives and control policies suitable for multirobot motion planning; the modularity of our approach enables one to independently customize the designs of each of these components. Our approach is experimentally validated on a group of quadrocopters.
@article{vukosavljev-tro19,
title = {A modular framework for motion planning using safe-by-design motion primitives},
author = {Marijan Vukosavljev and Zachary Kroeze and Angela P. Schoellig and Mireille E. Broucke},
journal = {{IEEE Transactions on Robotics}},
year = {2019},
volume = {35},
number = {5},
pages = {1233--1252},
doi = {10.1109/TRO.2019.2923335},
urlvideo = {http://tiny.cc/modular-3alg},
urllink = {https://arxiv.org/abs/1905.00495},
abstract = {In this paper, we present a modular framework for solving a motion planning problem among a group of robots. The proposed framework utilizes a finite set of low-level motion primitives to generate motions in a gridded workspace. The constraints on allowable sequences of motion primitives are formalized through a maneuver automaton . At the high level, a control policy determines which motion primitive is executed in each box of the gridded workspace. We state general conditions on motion primitives to obtain provably correct behavior so that a library of safe-by-design motion primitives can be designed. The overall framework yields a highly robust design by utilizing feedback strategies at both the low and high levels. We provide specific designs for motion primitives and control policies suitable for multirobot motion planning; the modularity of our approach enables one to independently customize the designs of each of these components. Our approach is experimentally validated on a group of quadrocopters.}
} Trajectory tracking for quadrotors with attitude control on $\mathcal{S}^2\times \mathcal{S}^1$D. Kooijman, A. P. Schoellig, and D. J. Antunesin Proc. of the European Control Conference (ECC), 2019, p. 4002–4009.
![]()
![]()
![]()
The control of a quadrotor is typically split into two subsequent problems: finding desired accelerations to control its position, and controlling its attitude and the total thrust to track these accelerations and to track a yaw angle reference. While the thrust vector, generating accelerations, and the angle of rotation about the thrust vector, determining the yaw angle, can be controlled independently, most attitude control strategies in the literature, relying on representations in terms of quaternions, rotation matrices or Euler angles, result in an unnecessary coupling between the control of the thrust vector and of the angle about this vector. This leads, for instance, to undesired position tracking errors due to yaw tracking errors. In this paper we propose to tackle the attitude control problem using an attitude representation in the Cartesian product of the 2-sphere and the 1-sphere, denoted by $\mathcal{S}^2\times \mathcal{S}^1$. We propose a non-linear tracking control law on $\mathcal{S}^2\times \mathcal{S}^1$ that decouples the control of the thrust vector and of the angle of rotation about the thrust vector, and guarantees almost global asymptotic stability. Simulation results highlight the advantages of the proposed approach over previous approaches.
@INPROCEEDINGS{kooijman-ecc19,
author = {Dave Kooijman and Angela P. Schoellig and Duarte J. Antunes},
title = {Trajectory Tracking for Quadrotors with Attitude Control on {$\mathcal{S}^2\times \mathcal{S}^1$}},
booktitle = {{Proc. of the European Control Conference (ECC)}},
year = {2019},
pages = {4002--4009},
abstract = {The control of a quadrotor is typically split into two subsequent problems: finding desired accelerations to control its position, and controlling its attitude and the total thrust to track these accelerations and to track a yaw angle reference. While the thrust vector, generating accelerations, and the angle of rotation about the thrust vector, determining the yaw angle, can be controlled independently, most attitude control strategies in the literature, relying on representations in terms of quaternions, rotation matrices or Euler angles, result in an unnecessary coupling between the control of the thrust vector and of the angle about this vector. This leads, for instance, to undesired position tracking errors due to yaw tracking errors. In this paper we propose to tackle the attitude control problem using an attitude representation in the Cartesian product of the 2-sphere and the 1-sphere, denoted by $\mathcal{S}^2\times \mathcal{S}^1$. We propose a non-linear tracking control law on $\mathcal{S}^2\times \mathcal{S}^1$ that decouples the control of the thrust vector and of the angle of rotation about the thrust vector, and guarantees almost global asymptotic stability. Simulation results highlight the advantages of the proposed approach over previous approaches.},
} Adaptive model predictive control for high-accuracy trajectory tracking in changing conditionsK. Pereida and A. P. Schoelligin Proc. of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2018, p. 7831–7837.
![]()
![]()
![]()
![]()
Robots and automated systems are increasingly being introduced to unknown and dynamic environments where they are required to handle disturbances, unmodeled dynamics, and parametric uncertainties. Robust and adaptive control strategies are required to achieve high performance in these dynamic environments. In this paper, we propose a novel adaptive model predictive controller that combines model predictive control (MPC) with an underlying L_1 adaptive controller to improve trajectory tracking of a system subject to unknown and changing disturbances. The L_1 adaptive controller forces the system to behave in a predefined way, as specified by a reference model. A higher-level model predictive controller then uses this reference model to calculate the optimal reference input based on a cost function, while taking into account input and state constraints. We focus on the experimental validation of the proposed approach and demonstrate its effectiveness in experiments on a quadrotor. We show that the proposed approach has a lower trajectory tracking error compared to non-predictive, adaptive approaches and a predictive, non-adaptive approach, even when external wind disturbances are applied.
@INPROCEEDINGS{pereida-iros18,
author={Karime Pereida and Angela P. Schoellig},
title={Adaptive Model Predictive Control for High-Accuracy Trajectory Tracking in Changing Conditions},
booktitle={{Proc. of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}},
year={2018},
pages={7831--7837},
urllink={https://arxiv.org/abs/1807.05290},
abstract={Robots and automated systems are increasingly being introduced to unknown and dynamic environments where they are required to handle disturbances, unmodeled dynamics, and parametric uncertainties. Robust and adaptive control strategies are required to achieve high performance in these dynamic environments. In this paper, we propose a novel adaptive model predictive controller that combines model predictive control (MPC) with an underlying L_1 adaptive controller to improve trajectory tracking of a system subject to unknown and changing disturbances. The L_1 adaptive controller forces the system to behave in a predefined way, as specified by a reference model. A higher-level model predictive controller then uses this reference model to calculate the optimal reference input based on a cost function, while taking into account input and state constraints. We focus on the experimental validation of the proposed approach and demonstrate its effectiveness in experiments on a quadrotor. We show that the proposed approach has a lower trajectory tracking error compared to non-predictive, adaptive approaches and a predictive, non-adaptive approach, even when external wind disturbances are applied.},
} ![]() Hybrid model predictive control for crosswind stabilization of hybrid airshipsJ. F. M. Foerster, M. K. Helwa, X. Du, and A. P. Schoelligin Proc. of the International Symposium on Experimental Robotics (ISER), 2018, pp. 499-510.
Hybrid model predictive control for crosswind stabilization of hybrid airshipsJ. F. M. Foerster, M. K. Helwa, X. Du, and A. P. Schoelligin Proc. of the International Symposium on Experimental Robotics (ISER), 2018, pp. 499-510.
![]()
![]()
![]()
![]()
Hybrid airships are heavier-than-air vehicles that generate a majority of the lift using buoyancy. The resulting high energy efficiency during operation and short take-off and landing distances make this vehicle class very suited for a number of logistics applications. However, the range of safe operating conditions can be limited due to a high susceptibility to crosswinds during taxiing, take-off and landing. The goal of this work is to design and implement an automated counter-gust system (CGS) that stabilizes a hybrid airship against wind disturbances during ground operations by controlling thrusters that are mounted to the wingtips. The CGS controller should compute optimal control inputs, run autonomously without pilot intervention, be computationally efficient to run on onboard hardware, and be flexible regarding adaption to future aircraft.
@INPROCEEDINGS{foerster-iser18,
author={Julian F. M. Foerster and Mohamed K. Helwa and Xintong Du and Angela P. Schoellig},
title={Hybrid Model Predictive Control for Crosswind Stabilization of Hybrid Airships},
booktitle={{Proc. of the International Symposium on Experimental Robotics (ISER)}},
year={2018},
pages={499-510},
doi={10.1007/978-3-030-33950-0_43},
urllink={https://link.springer.com/chapter/10.1007/978-3-030-33950-0_43},
abstract={Hybrid airships are heavier-than-air vehicles that generate a majority of the lift using buoyancy. The resulting high energy efficiency during operation and short take-off and landing distances make this vehicle class very suited for a number of logistics applications. However, the range of safe operating conditions can be limited due to a high susceptibility to crosswinds during taxiing, take-off and landing. The goal of this work is to design and implement an automated counter-gust system (CGS) that stabilizes a hybrid airship against wind disturbances during ground operations by controlling thrusters that are mounted to the wingtips. The CGS controller should compute optimal control inputs, run autonomously without pilot intervention, be computationally efficient to run on onboard hardware, and be flexible regarding adaption to future aircraft.},
} ![]() A framework for multi-vehicle navigation using feedback-based motion primitivesM. Vukosavljev, Z. Kroeze, M. E. Broucke, and A. P. Schoelligin Proc. of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2017, p. 223–229.
A framework for multi-vehicle navigation using feedback-based motion primitivesM. Vukosavljev, Z. Kroeze, M. E. Broucke, and A. P. Schoelligin Proc. of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2017, p. 223–229.
![]()
![]()
![]()
![]()
![]()
![]()
We present a hybrid control framework for solving a motion planning problem among a collection of heterogenous agents. The proposed approach utilizes a finite set of low-level motion primitives, each based on a piecewise affine feedback control, to generate complex motions in a gridded workspace. The constraints on allowable sequences of successive motion primitives are formalized through a maneuver automaton. At the higher level, a control policy generated by a shortest path non-deterministic algorithm determines which motion primitive is executed in each box of the gridded workspace. The overall framework yields a highly robust control design on both the low and high levels. We experimentally demonstrate the efficacy and robustness of this framework for multiple quadrocopters maneuvering in a 2D or 3D workspace.
@INPROCEEDINGS{vukosavljev-iros17,
author={Marijan Vukosavljev and Zachary Kroeze and Mireille E. Broucke and Angela P. Schoellig},
title={A Framework for Multi-Vehicle Navigation Using Feedback-Based Motion Primitives},
booktitle={{Proc. of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}},
year={2017},
pages={223--229},
doi={10.1109/IROS.2017.8202161},
urllink={https://arxiv.org/abs/1707.06988},
urlvideo={https://www.youtube.com/watch?v=qhDQyvYNVEc},
urlslides = {../../wp-content/papercite-data/slides/vukosavljev-iros17-slides.pdf},
abstract={We present a hybrid control framework for solving a motion planning problem among a collection of heterogenous agents. The proposed approach utilizes a finite set of low-level motion primitives, each based on a piecewise affine feedback control, to generate complex motions in a gridded workspace. The constraints on allowable sequences of successive motion primitives are formalized through a maneuver automaton. At the higher level, a control policy generated by a shortest path non-deterministic algorithm determines which motion primitive is executed in each box of the gridded workspace. The overall framework yields a highly robust control design on both the low and high levels. We experimentally demonstrate the efficacy and robustness of this framework for multiple quadrocopters maneuvering in a 2D or 3D workspace.},
} ![]() On the construction of safe controllable regions for affine systems with applications to roboticsM. K. Helwa and A. P. Schoelligin Proc. of the IEEE Conference on Decision and Control (CDC), 2016, pp. 3000-3005.
On the construction of safe controllable regions for affine systems with applications to roboticsM. K. Helwa and A. P. Schoelligin Proc. of the IEEE Conference on Decision and Control (CDC), 2016, pp. 3000-3005.
![]()
![]()
![]()
![]()
![]()
![]()
This paper studies the problem of constructing in-block controllable (IBC) regions for affine systems. That is, we are concerned with constructing regions in the state space of affine systems such that all the states in the interior of the region are mutually accessible through the region’s interior by applying uniformly bounded inputs. We first show that existing results for checking in-block controllability on given polytopic regions cannot be easily extended to address the question of constructing IBC regions. We then explore the geometry of the problem to provide a computationally efficient algorithm for constructing IBC regions. We also prove the soundness of the algorithm. Finally, we use the proposed algorithm to construct safe speed profiles for fully-actuated robots and for ground robots modeled as unicycles with acceleration limits.
@INPROCEEDINGS{helwa-cdc16,
author = {Mohamed K. Helwa and Angela P. Schoellig},
title = {On the construction of safe controllable regions for affine systems with applications to robotics},
booktitle = {{Proc. of the IEEE Conference on Decision and Control (CDC)}},
year = {2016},
pages = {3000-3005},
doi = {10.1109/CDC.2016.7798717},
urllink = {https://arxiv.org/abs/1610.01243},
urlslides = {../../wp-content/papercite-data/slides/helwa-cdc16-slides.pdf},
urlvideo = {https://youtu.be/s_N7zTtCjd0},
abstract = {This paper studies the problem of constructing in-block controllable (IBC) regions for affine systems. That is, we are concerned with constructing regions in the state space of affine systems such that all the states in the interior of the region are mutually accessible through the region’s interior by applying uniformly bounded inputs. We first show that existing results for checking in-block controllability on given polytopic regions cannot be easily extended to address the question of constructing IBC regions. We then explore the geometry of the problem to provide a computationally efficient algorithm for constructing IBC regions. We also prove the soundness of the algorithm. Finally, we use the proposed algorithm to construct safe speed profiles for fully-actuated robots and for ground robots modeled as unicycles with acceleration limits.},
} ![]() Safe and robust quadrotor maneuvers based on reach controlM. Vukosavljev, I. Jansen, M. E. Broucke, and A. P. Schoelligin Proc. of the IEEE International Conference on Robotics and Automation (ICRA), 2016, pp. 5677-5682.
Safe and robust quadrotor maneuvers based on reach controlM. Vukosavljev, I. Jansen, M. E. Broucke, and A. P. Schoelligin Proc. of the IEEE International Conference on Robotics and Automation (ICRA), 2016, pp. 5677-5682.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
In this paper, we investigate the synthesis of piecewise affine feedback controllers to execute safe and robust quadrocopter maneuvers. The methodology is based on formulating the problem as a reach control problem on a polytopic state space. Reach control has so far only been developed in theory and has not been tested experimentally in a real system before. We demonstrate that these theoretical tools can achieve aggressive, albeit safe and robust, quadrocopter maneuvers without the need for a predefined open-loop reference trajectory. In a proof-of-concept demonstration, the reach controller is implemented in one translational direction while the other degrees of freedom are stabilized by separate controllers. Experimental results on a quadrocopter show the effectiveness and robustness of this control approach.
@INPROCEEDINGS{vukosavljev-icra16,
author = {Marijan Vukosavljev and Ivo Jansen and Mireille E. Broucke and Angela P. Schoellig},
title = {Safe and robust quadrotor maneuvers based on reach control},
booktitle = {{Proc. of the IEEE International Conference on Robotics and Automation (ICRA)}},
year = {2016},
pages = {5677-5682},
doi = {10.1109/ICRA.2016.7487789},
urllink = {https://arxiv.org/abs/1610.02385},
urlvideo={https://youtu.be/l4vdxdmd2xc},
urlslides={../../wp-content/papercite-data/slides/vukosavljev-icra16-slides.pdf},
urlslides2={../../wp-content/papercite-data/slides/vukosavljev-icra16-slides2.pdf},
abstract = {In this paper, we investigate the synthesis of piecewise affine feedback controllers to execute safe and robust quadrocopter maneuvers. The methodology is based on formulating the problem as a reach control problem on a polytopic state space. Reach control has so far only been developed in theory and has not been tested experimentally in a real system before. We demonstrate that these theoretical tools can achieve aggressive, albeit safe and robust, quadrocopter maneuvers without the need for a predefined open-loop reference trajectory. In a proof-of-concept demonstration, the reach controller is implemented in one translational direction while the other degrees of freedom are stabilized by separate controllers. Experimental results on a quadrocopter show the effectiveness and robustness of this control approach.}
} ![]() Speed daemon: experience-based mobile robot speed schedulingC. J. Ostafew, A. P. Schoellig, T. D. Barfoot, and J. Collierin Proc. of the International Conference on Computer and Robot Vision (CRV), 2014, pp. 56-62. Best Robotics Paper Award.
Speed daemon: experience-based mobile robot speed schedulingC. J. Ostafew, A. P. Schoellig, T. D. Barfoot, and J. Collierin Proc. of the International Conference on Computer and Robot Vision (CRV), 2014, pp. 56-62. Best Robotics Paper Award.
![]()
![]()
![]()
![]()
A time-optimal speed schedule results in a mobile robot driving along a planned path at or near the limits of the robot’s capability. However, deriving models to predict the effect of increased speed can be very difficult. In this paper, we present a speed scheduler that uses previous experience, instead of complex models, to generate time-optimal speed schedules. The algorithm is designed for a vision-based, path-repeating mobile robot and uses experience to ensure reliable localization, low path-tracking errors, and realizable control inputs while maximizing the speed along the path. To our knowledge, this is the first speed scheduler to incorporate experience from previous path traversals in order to address system constraints. The proposed speed scheduler was tested in over 4 km of path traversals in outdoor terrain using a large Ackermann-steered robot travelling between 0.5 m/s and 2.0 m/s. The approach to speed scheduling is shown to generate fast speed schedules while remaining within the limits of the robot’s capability.
@INPROCEEDINGS{ostafew-crv14,
author = {Chris J. Ostafew and Angela P. Schoellig and Timothy D. Barfoot and J. Collier},
title = {Speed daemon: experience-based mobile robot speed scheduling},
booktitle = {{Proc. of the International Conference on Computer and Robot Vision (CRV)}},
pages = {56-62},
year = {2014},
doi = {10.1109/CRV.2014.16},
urlvideo = {https://youtu.be/Pu3_F6k6Fa4?list=PLC12E387419CEAFF2},
abstract = {A time-optimal speed schedule results in a mobile robot driving along a planned path at or near the limits of the robot's capability. However, deriving models to predict the effect of increased speed can be very difficult. In this paper, we present a speed scheduler that uses previous experience, instead of complex models, to generate time-optimal speed schedules. The algorithm is designed for a vision-based, path-repeating mobile robot and uses experience to ensure reliable localization, low path-tracking errors, and realizable control inputs while maximizing the speed along the path. To our knowledge, this is the first speed scheduler to incorporate experience from previous path traversals in order to address system constraints. The proposed speed scheduler was tested in over 4 km of path traversals in outdoor terrain using a large Ackermann-steered robot travelling between 0.5 m/s and 2.0 m/s. The approach to speed scheduling is shown to generate fast speed schedules while remaining within the limits of the robot's capability.},
note = {Best Robotics Paper Award}
} ![]() Dance of the flying machines: methods for designing and executing an aerial dance choreographyF. Augugliaro, A. P. Schoellig, and R. D’AndreaIEEE Robotics Automation Magazine, vol. 20, iss. 4, pp. 96-104, 2013.
Dance of the flying machines: methods for designing and executing an aerial dance choreographyF. Augugliaro, A. P. Schoellig, and R. D’AndreaIEEE Robotics Automation Magazine, vol. 20, iss. 4, pp. 96-104, 2013.
![]()
![]()
![]()
![]()
![]()
Imagine a troupe of dancers flying together across a big open stage, their movement choreographed to the rhythm of the music. Their performance is both coordinated and skilled; the dancers are well rehearsed, and the choreography well suited to their abilities. They are no ordinary dancers, however, and this is not an ordinary stage. The performers are quadrocopters, and the stage is the ETH Zurich Flying Machine Arena, a state-of-the-art mobile testbed for aerial motion control research.
@ARTICLE{augugliaro-ram13,
author = {Federico Augugliaro and Angela P. Schoellig and Raffaello D'Andrea},
title = {Dance of the Flying Machines: Methods for Designing and Executing an Aerial Dance Choreography},
journal = {{IEEE Robotics Automation Magazine}},
volume = {20},
number = {4},
pages = {96-104},
year = {2013},
doi = {10.1109/MRA.2013.2275693},
urlvideo={http://youtu.be/NRL_1ozDQCA?t=21s},
urlslides={../../wp-content/papercite-data/slides/augugliaro-ram13-slides.pdf},
abstract = {Imagine a troupe of dancers flying together across a big open stage, their movement choreographed to the rhythm of the music. Their performance is both coordinated and skilled; the dancers are well rehearsed, and the choreography well suited to their abilities. They are no ordinary dancers, however, and this is not an ordinary stage. The performers are quadrocopters, and the stage is the ETH Zurich Flying Machine Arena, a state-of-the-art mobile testbed for aerial motion control research.}
} ![]() Generation of collision-free trajectories for a quadrocopter fleet: a sequential convex programming approachF. Augugliaro, A. P. Schoellig, and R. D’Andreain Proc. of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2012, pp. 1917-1922.
Generation of collision-free trajectories for a quadrocopter fleet: a sequential convex programming approachF. Augugliaro, A. P. Schoellig, and R. D’Andreain Proc. of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2012, pp. 1917-1922.
![]()
![]()
![]()
![]()
This paper presents an algorithm that generates collision-free trajectories in three dimensions for multiple vehicles within seconds. The problem is cast as a non-convex optimization problem, which is iteratively solved using sequential convex programming that approximates non-convex constraints by using convex ones. The method generates trajectories that account for simple dynamics constraints and is thus independent of the vehicle’s type. An extensive a posteriori vehicle-specific feasibility check is included in the algorithm. The algorithm is applied to a quadrocopter fleet. Experimental results are shown.
@INPROCEEDINGS{augugliaro-iros12,
author = {Federico Augugliaro and Angela P. Schoellig and Raffaello D'Andrea},
title = {Generation of collision-free trajectories for a quadrocopter fleet: A sequential convex programming approach},
booktitle = {{Proc. of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}},
pages = {1917-1922},
year = {2012},
doi = {10.1109/IROS.2012.6385823},
urlvideo = {https://youtu.be/wwK7WvvUvlI?list=PLD6AAACCBFFE64AC5},
abstract = {This paper presents an algorithm that generates collision-free trajectories in three dimensions for multiple vehicles within seconds. The problem is cast as a non-convex optimization problem, which is iteratively solved using sequential convex programming that approximates non-convex constraints by using convex ones. The method generates trajectories that account for simple dynamics constraints and is thus independent of the vehicle's type. An extensive a posteriori vehicle-specific feasibility check is included in the algorithm. The algorithm is applied to a quadrocopter fleet. Experimental results are shown.}
} ![]() Feed-forward parameter identification for precise periodic quadrocopter motionsA. P. Schoellig, C. Wiltsche, and R. D’Andreain Proc. of the American Control Conference (ACC), 2012, pp. 4313-4318.
Feed-forward parameter identification for precise periodic quadrocopter motionsA. P. Schoellig, C. Wiltsche, and R. D’Andreain Proc. of the American Control Conference (ACC), 2012, pp. 4313-4318.
![]()
![]()
![]()
![]()
![]()
This paper presents an approach for precisely tracking periodic trajectories with a quadrocopter. In order to improve temporal and spatial tracking performance, we propose a feed-forward strategy that adapts the motion parameters sent to the vehicle controller. The motion parameters are either adjusted on the fly or, in order to avoid initial transients, identified prior to the flight performance. We outline an identification scheme that tunes parameters for a large class of periodic motions, and requires only a small number of identification experiments prior to flight. This reduced identification is based on analysis and experiments showing that the quadrocopter’s closed-loop dynamics can be approximated by three directionally decoupled linear systems. We show the effectiveness of this approach by performing a sequence of periodic motions on real quadrocopters using the tuned parameters obtained by the reduced identification.
@INPROCEEDINGS{schoellig-acc12,
author = {Angela P. Schoellig and Clemens Wiltsche and Raffaello D'Andrea},
title = {Feed-forward parameter identification for precise periodic quadrocopter motions},
booktitle = {{Proc. of the American Control Conference (ACC)}},
pages = {4313-4318},
year = {2012},
doi = {10.1109/ACC.2012.6315248},
urlvideo = {http://tiny.cc/MusicInMotion},
urlslides = {../../wp-content/papercite-data/slides/schoellig-acc12-slides.pdf},
abstract = {This paper presents an approach for precisely tracking periodic trajectories with a quadrocopter. In order to improve temporal and spatial tracking performance, we propose a feed-forward strategy that adapts the motion parameters sent to the vehicle controller. The motion parameters are either adjusted on the fly or, in order to avoid initial transients, identified prior to the flight performance. We outline an identification scheme that tunes parameters for a large class of periodic motions, and requires only a small number of identification experiments prior to flight. This reduced identification is based on analysis and experiments showing that the quadrocopter's closed-loop dynamics can be approximated by three directionally decoupled linear systems. We show the effectiveness of this approach by performing a sequence of periodic motions on real quadrocopters using the tuned parameters obtained by the reduced identification.}
}